Afstudeerproject GroepT Informatica
2005-2006
Verslag
van het proefproject rond de
klantenreacties
bij VRT-TV
Joris Bekaert
Stijn Mostmans
Rudy Vanoverschelde
|
|
|
Start
|
Einde
|
Gewicht
|
Rudy
|
Joris
|
Stijn
|
|
|
|
|
|
|
%
|
%
|
%
|
|
Afbakening
project - probleemdefinitie - systeemeisen
|
04/10/05
|
17/11/05
|
|
|
|
|
|
|
Startvergadering
+ samenvatting
|
04/10/05
|
05/10/05
|
10
|
33
|
33
|
33
|
|
|
Situeer eindwerk in algemene structuur van VRT
|
04/10/05
|
10/10/05
|
10
|
50
|
50
|
0
|
|
|
Doornemen
informatie John
|
07/10/05
|
14/10/05
|
30
|
33
|
33
|
33
|
|
|
Gesprek Wouter
Sterckx + samenvatting
|
12/10/05
|
15/10/05
|
10
|
100
|
0
|
0
|
|
|
Interview John
Van Vreckem + samenvatting
|
14/10/05
|
22/10/05
|
40
|
33
|
33
|
33
|
|
|
Bezoek RTBF + samenvatting
|
18/10/05
|
22/10/05
|
10
|
100
|
0
|
0
|
|
|
Systeem
Diagramma
|
24/10/05
|
26/10/05
|
10
|
100
|
0
|
0
|
|
|
Schets context
diagramma
|
26/10/05
|
28/10/05
|
10
|
100
|
0
|
0
|
|
|
Vergadering
stuurgroep + verslag
|
26/10/05
|
07/11/05
|
10
|
100
|
0
|
0
|
|
|
Brainstorm en overleg met mensen van de stuurgroep
+ samenvattingen
|
08/11/05
|
02/12/05
|
40
|
75
|
25
|
0
|
|
|
Functional
Decomposition Diagram
|
04/10/05
|
15/11/05
|
40
|
33
|
33
|
33
|
|
|
Cause and
effects, system improvements table
|
06/11/05
|
17/11/05
|
50
|
40
|
20
|
40
|
|
|
Definities Use
Cases
|
07/11/05
|
07/11/05
|
30
|
100
|
0
|
0
|
|
|
Event Response
list
|
06/11/05
|
17/11/05
|
30
|
100
|
0
|
0
|
|
|
Rapportering aan de IT-afdeling + verslagen
|
10/11/05
|
14/11/05
|
10
|
75
|
25
|
0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
62,60
|
19,81
|
17,59
|
|
|
|
|
|
|
|
|
|
|
Analyse en ontwerp van de database
|
15/11/05
|
30/01/06
|
|
|
|
|
|
|
Eerste logische
versie database
|
15/11/05
|
25/11/05
|
30
|
20
|
0
|
80
|
|
|
Tweede logische
versie database
|
25/11/05
|
15/12/05
|
30
|
100
|
0
|
0
|
|
|
Derde logische
versie database
|
15/12/05
|
31/12/05
|
30
|
100
|
0
|
0
|
|
|
Studie Hibernate
framework
|
15/11/05
|
31/01/06
|
40
|
50
|
0
|
50
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
66,15
|
0,00
|
33,85
|
|
|
|
|
|
|
|
|
|
|
Object-georiënteerde analyse en ontwerp
|
15/11/05
|
15/01/06
|
|
|
|
|
|
|
Use case beschrijvingen eerste iteratie
|
15/11/05
|
04/12/05
|
100
|
10
|
90
|
0
|
|
|
Studie
Struts-framework
|
15/11/05
|
20/12/05
|
40
|
75
|
25
|
0
|
|
|
Studie
web-technologieen
|
15/11/05
|
20/12/05
|
40
|
20
|
80
|
0
|
|
|
Ontwerp
OO-model businesslaag in Together
|
20/12/05
|
15/01/06
|
30
|
100
|
0
|
0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
37,14
|
62,86
|
0,00
|
|
|
|
|
|
|
|
|
|
|
Coderen en
testen
|
01/01/06
|
15/04/06
|
|
|
|
|
|
|
Implementatie
fysieke databank
|
01/01/06
|
31/01/06
|
40
|
100
|
0
|
0
|
|
|
Implementatie
Hibernate
|
15/01/06
|
15/02/06
|
40
|
80
|
0
|
20
|
|
|
Implementatie
bussinesslaag
|
01/01/06
|
15/04/06
|
40
|
100
|
0
|
0
|
|
|
Implementatie
Struts
|
15/01/06
|
15/04/06
|
40
|
80
|
20
|
0
|
|
|
Implementatie
presentatielaag
|
31/01/06
|
15/04/06
|
40
|
0
|
100
|
0
|
|
|
Testen
|
31/01/06
|
15/04/06
|
10
|
60
|
0
|
40
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
71,43
|
22,86
|
5,71
|
|
|
|
|
|
|
|
|
|
|
Boek
|
15/04/06
|
15/05/06
|
|
35
|
50
|
15
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Totaal
|
|
54,47
|
31,10
|
14,43
|
Dit
document bevat het verslag van het “Proefproject voor de klantenrelaties van
VRT-televisie” dat als ondernemingsproject werd uitgevoerd door Rudy
Vanoverschelde, Stijn Mostmans en Joris Bekaert in opdracht van de dienst
communicatie van VRT-televisie. Het
verslag bevat alle elementen die nodig zijn om tot een goed begrip te komen van
alles wat in de loop van dit project werd gerealiseerd.
Het
eindproduct van dit eindwerk is natuurlijk de applicatie zelf. Deze is te bekijken op de CD-ROM die zich in
de bijlagen bevindt.
Het verslag
bestaat uit vier grote hoofdstukken. Het
eerste hoofdstuk bespreekt de definitie van de scope van het project en de
aanpak van de probleemanalyse, de analyse van de vereisten en de
systeemarchitectuur die op basis hiervan werd voorgesteld.
Het tweede
hoofdstuk gaat dieper in op het ontwerp van de database. Hierbij zullen de verschillende fases, die geleid
hebben tot het uiteindelijke datamodel, chronologisch worden besproken. In dit hoofdstuk zal ook de nodige aandacht
worden geschonken aan het Hibernate framework, dat gebruikt werd als middleware
tussen de businesslaag en de databanklaag.
Het derde hoofdstuk
bespreekt het ontwerp van het businessmodel, met speciale aandacht voor de
gebruikte patronen. Ook wordt hier de
nodige aandacht besteed aan het framework struts, dat gebruikt werd als
middleware tussen de businesslaag en de interface.
In een vierde
en laatste hoofdstuk tenslotte staat de implementatie zelf centraal. Hierbij worden eerst de gebruikte
technologieën stuk voor stuk besproken, met uitzondering van Hibernate en
Struts. Vervolgens wordt ingegaan op de
functionaliteit van de applicatie die tijdens dit project werd gerealiseerd aan
de hand van een aantal screenshots van de webinterface. Tenslotte worden enkele tests besproken die
uitgevoerd werden om de implementatie te kunnen evalueren.
Om een goed
overzicht te behouden tijdens het lezen van dit verslag, werden de
verschillende fases van dit project samengevat in een schema. Dit kan u terugvinden op de volgende
bladzijde. Dit schema is gebaseerd op
het schema dat Whitten, Bentley en Dittman ontwierpen voor hun boek Systems
Analysis and Design Methods. Het werd aangepast aan de context van dit
project. Aan het begin van
elk hoofdstuk zal teruggekeerd worden naar dit schema om de fases die binnen
het hoofdstuk besproken worden te situeren binnen het verslag.
De volgende
tabel geeft een overzicht van de timing die gevolgd werd bij het realiseren van
de verschillende fases.
|
Afbakening project - probleemdefinitie - systeemeisen
|
04/10/05
|
17/11/05
|
|
Analyse en ontwerp van de database
|
15/11/05
|
30/01/06
|
|
Object-georiënteerde analyse en ontwerp
|
15/11/05
|
15/01/06
|
|
Coderen en testen
|
01/01/06
|
15/04/06
|
|
Verslag
|
15/04/06
|
15/05/06
|
In dit eerste hoofdstuk bespreken we de eerste drie fases uit het
project namelijk de definitie van de scope en de probleemanalyse, de analyse van de vereisten en een voorstel
voor systeemarchitectuur. In het
algemene schema dat in de inleiding werd voorgesteld, situeren deze fases zich
als volgt:
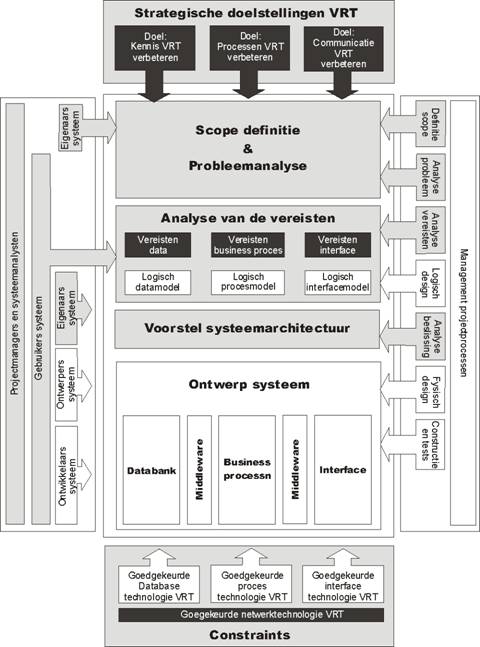
Hierbij dient te worden opgemerkt dat het
logisch datamodel, het logisch procesmodel en het logisch interfacemodel elk
pas in één van de volgende fases werden ontwikkeld.
In deze eerste paragraaf zal de scope van dit
project duidelijk worden afgelijnd. Dit zal gebeuren door een omschrijving van
de bedrijfsfuncties van VRT televisie, de instelling in opdracht waarvan dit
project werd uitgevoerd. Vervolgens zal het algemene project van VRT-televisie
besproken worden waarbinnen dit eindwerk zich situeert.
De Vlaamse Radio en Televisie is als openbare
omroep gekend door zowat iedereen in Vlaanderen. Traditioneel zijn tv en radio de grote
pijlers van de omroep. Maar in het snel
veranderende medialandschap stelt VRT zich ook tot doel nieuwe media ten volle
te benutten.
Dit blijkt onder meer uit onderstaand algemeen
organigram. Naast de
beleidsondersteunende, financiële en HR-functies zijn de belangrijkste
onderdelen tv, radio
en strategie, technologie en
innovatie.

De
VRT-televisie maakt zich sterk zijn wettelijke opdracht op marktgerichte manier
waar te maken. Dat betekent het brede
publiek bereiken en extra aandacht besteden aan doelgroepen die niet
interessant zijn voor commerciële zenders.
Op 2 tv-kanalen worden de 3 netten geprogrammeerd: het “verbredende net”
Eén, het “verdiepende net” Canvas en een jeugdnet “Ketnet”. In de zomer van 2004 werd een 4de
tijdelijk net Sporza opgericht op een apart 3de tv-kanaal. De tv-programma’s van Sporza vallen nu echter
terug onder Eén of Canvas.
Zoals bij televisie richt ook het
radioaanbod zich naar specifieke doelgroepen.
Iedereen in Vlaanderen zou zich ergens moeten kunnen terugvinden bij
Radio1, Radio2, Donna, Studio Brussel of Klara.
Wereldwijd kan RVi (Radio Vlaanderen Internationaal) worden
ontvangen. Daarnaast biedt de VRT-radio
ook een DAB (digital audio broadcasting) pakket aan met onder meer DABklassiek.
Technologische,
maatschappelijke en economische evoluties zorgen voor een veranderend en meer
gediversifieerd mediagebruik. De sites
van de verschillende radio- en televisienetten en programma’s spelen hierop
in. Op vrtnieuws.net bijvoorbeeld kan iedereen
zelf op zoek gaan in een ruim aanbod van beeld, geluid en tekst. Ook het nieuwe vrt-aanbod voor digitale
televisie sluit aan bij dit wijzigend medialandschap. Nieuwe mogelijkheden zoals video-on-demand en
het ontsluiten van het beeldarchief bieden zich aan.
Dit
afstudeerproject kadert in het ruimer project “Klantenrelaties. Interne en
externe communicatie” van de dienst communicatie van VRT-televisie. Dit project heeft als doel de communicatie
tussen de klanten en de VRT te verbeteren.
De dienst Televisie krijgt elk jaar een
zeer groot aantal reacties te verwerken, zowel telefonisch als via mail. Tot op heden worden deze zo goed mogelijk
beantwoord door de programmamedewerkers.
Een gestructureerde registratie hiervan is onbestaand.
Doel van het ruimere project is het
probleem verder te onderzoeken en een oplossing te formuleren. Dit om enerzijds
de klantentevredenheid te verhogen en anderzijds om een instrument te creëren
om de kwaliteit van de diensten te verbeteren.
Daarom werd
gestart met een ruim onderzoek waarin een groot aantal mensen werden betrokken:
·
Er
werd een stuurgroep opgericht
·
Er
werd een enquête uitgevoerd
·
Er
werd nagegaan hoe deze problematiek op andere plaatsen werd aangepakt, zowel
intern als extern
De belangrijkste conclusie van dit
onderzoek was dat er nood was aan een centrale registratie van de reacties,
zowel van de reacties via e-mail als van de telefonische reacties (via een
intern call centre).
Op basis
van de resultaten van het onderzoek werd een project van drie jaar gestart. Dit
project werd als volgt gepland:
2005: Start- en aanloopfase
·
De
oprichting van een stuurgroep die het project coördineert en een beleid
uitwerkt (policy & best practices)
·
De
eerste stappen worden gezet om de klachtenrapportering te verbeteren
·
Binnen
een aantal diensten wordt geëxperimenteerd met een eerste vorm van registratie,
waarbij gewerkt wordt met standaardantwoorden en een standaardindeling van de
reacties (reactie, vraag, suggestie, felicitatie, klacht).
2006: Pilootproject
Tijdens deze fase
worden de nodige hulpmiddelen ontwikkeld om de definitieve klachtenregistratie
te realiseren, zowel voor de klachten die binnenkomen via een webformulier als
via telefoon.
In deze
fase zal ook gestart worden met een experimentele klantendienst, die zich zowel
met telefonische reacties als met de reacties via mail zal bezighouden. De
registratie wordt in deze fase gecentraliseerd. De afhandeling van de klachten
wordt reeds deels gedecentraliseerd. Tijdens deze fase wordt gefocust op de
reacties van klanten over de zender Eén.
De
bedoeling is dat er een tool wordt ontwikkeld of aangekocht voor de registratie
van reacties in een database, voor het beheer van de reacties en voor het maken
van een rapportering.
2007: Klantendienst operationeel
In deze
fase wordt de klantendienst voor TV operationeel, zowel voor telefonische
reacties als voor reacties die via het webformulier worden gegeven.
Basisidee
is dat de reacties centraal worden geregistreerd en bijgehouden, maar
decentraal, door de verschillende afzonderlijke diensten worden opgevolgd.
In deze
fase wordt het webformulier ook toegepast voor alle netten en voor programma’s
die door externen worden geproduceerd.
Het eindwerk waarvan het verslag hier voorligt
is te situeren binnen de tweede fase van het project, de fase van het
proefproject. Doelstelling van het
eindwerk was om een applicatie te ontwikkelen die (1) toelaat om reacties van
klanten van Eén te registreren via een interface die toegankelijk is via de
website van Eén en (2) die werknemers van de dienst communicatie en van VRT
toelaat om klantenreacties te beheren. Deze
applicatie kon dan in de testomgeving worden ingezet voor het beheer van de
reacties.
Concreet trad de dienst communicatie hier op
als klant. De dienst IT van VRT speelde
een ondersteunende rol. Zij zagen er
ondermeer op toe dat de standaarden van VRT werden gerespecteerd, zij zorgden
voor input en stelden de nodige infrastructuur ter beschikking.
De dienst communicatie speelde reeds van bij de
aanvang van het project met het idee om een applicatie van de Nederlandse firma
Trinicom aan te kopen en deze aan te passen aan de eigen noden.
In wat
volgt zal eerst de methodiek worden besproken die werd gevolgd om het probleem
van de klantenrelaties te analyseren en de systeemeisen in kaart te brengen.
Vervolgens zal de informatie die het resultaat is van deze analyse worden
voorgesteld aan de hand van enkele diagrammen en tabellen. Tenslotte zal kort
het voorstel van systeemarchitectuur worden besproken op een hoog niveau.
De
problemen waarvoor dit eindwerk mee een oplossing moest helpen bieden, werden in
de vorige paragrafen geïllustreerd. De dienst communicatie had het probleem reeds
goed gedocumenteerd bij de aanvang van dit eindwerk. Van deze documentatie werd
dankbaar gebruik gemaakt om een beeld te krijgen van het probleem van de
klachtenbehandeling en van de pijnpunten van het bestaande systeem. Deze
informatie werd aangevuld door een aantal presentaties die de dienst
communicatie gaf en door voorbereidende gesprekken met John Van Vreckem,
verantwoordelijke van het project “Klantenrelaties. Interne en externe
communicatie” binnen VRT.
Nadat het
probleem in kaart was gebracht werd gestart met het identificeren van de vereisten
voor het nieuwe systeem. Dit zowel op technisch als op inhoudelijk vlak. Hiervoor
werden verschillende bronnen van informatie aangeboord.
De
belangrijkste bron van informatie was uiteraard John Van Vreckem, die binnen
VRT optrad als aanspreekpunt en klant. Van hem werd een uitgebreid interview
afgenomen dat grondig werd voorbereid. De
informatie die van hem tijdens dit interview werd bekomen, was essentieel om
een goed beeld te krijgen van de verwachtingen. Het verslag van dit interview (zie bijlagen)
vormde tegelijk het vertrekpunt voor verdere analyse rond de verwerking van de
reacties, de zogenaamde back-office.
Er werden
verscheidene ontmoetingen georganiseerd met medewerkers van VRT die op de één
of andere manier betrokken zijn bij het opvolgen van de reacties. Het ging
hierbij zowel om inhoudelijke medewerkers als medewerkers die verantwoordelijk
zijn voor de meer technische aspecten van het afhandelen van de reacties. Ook
werden verschillende vergaderingen georganiseerd met de mensen van de dienst IT
om een beter zicht te krijgen op de technische omgeving waarbinnen de te
ontwikkelen applicatie moet functioneren.
De volgende
tabel geeft een overzicht van de vergaderingen en interviews waarvan de
verslagen als bijlagen werden toegevoegd.
|
Naam geïnterviewde
|
Functie
|
Datum
|
|
John Van
Vreckem
|
projectverantwoordelijke
bij de dienst communicatie van VRT
|
14/10/2005
|
|
Wouter Strerckx
|
service coördinator IT helpdesk
|
12/10/2005
|
|
stuurgroep klantenrelaties TV
|
Divers
|
28/10/2005
|
|
Diana Waumans
|
manager communicatie VRT-TV
|
09/11/2005
|
|
Rudy Depraetere
|
Verantwoordelijke nieuwsdienst binnen de
stuurgroep
|
09/11/2005
|
|
Linda Van Crombruggen
|
vertegenwoordiger
vrt-online binnen de stuurgroep
|
23/11/2005
|
|
Lesley Hernalsteen
|
vertegenwoordiger Eén in de stuurgroep
|
02/12/2005
|
Om het
spreekwoordelijke warme water niet opnieuw uit te vinden, werd ook nagegaan hoe
andere organisaties, die met een gelijkaardig probleem werden geconfronteerd
deze zaak hadden aangepakt en welke oplossingen zij hadden bedacht. De dienst communicatie had de beschikking over
de documentatie van een applicatie die door De Lijn werd gerealiseerd. De lectuur van deze documentatie leverde tal
van bruikbare ideeën op. Daarnaast werd
een bezoek gebracht aan de RTBF omdat ook zij een toepassing hebben ontwikkeld
om het probleem van de klantenreacties aan te pakken (zie bijlagen).
Tot slot
werd ook gekeken naar commerciële pakketten voor de registratie van klachten.
Concreet werd de werking van een pakket bestudeerd van het Nederlandse bedrijf
Trinicom.
Alle
bekomen informatie werd grondig geanalyseerd. Het resultaat van deze analyse is
terug te vinden in de volgende tabellen.
Onderstaand tabel geeft een goed overzicht van
de problemen en opportuniteiten van het vorige systeem en hun oorzaken en
gevolgen. Tegelijk worden de doelstellingen van het nieuwe systeem geschetst,
samen met de beperkingen waarmee het nieuwe systeem geconfronteerd wordt.
|
CAUSE AND EFFECT
ANALYSIS
|
SYSTEM IMPROVEMENT
OBJECTIVES
|
|
Problem or Opportunity
|
Causes and Effects
|
System Objective
|
System Constraint
|
|
·
Hoog aantal mails: kwart miljoen mails
per jaar voor de televisie. Verwacht
wordt dat het emailverkeer de volgende jaren explosief zal blijven stijgen.
|
·
De drempel om een reactie te versturen is
te laag.
·
Via email kunnen lange reacties, bijlagen
en spam binnenkomen.
·
De standaardantwoorden op het web zijn
niet altijd goed gestructureerd.
|
·
Reacties, waarvan het antwoord reeds op
het web te vinden is, moeten worden uitgesloten.
·
Een webformulier beperkt de lengte van de
reactie.
·
Filters inbouwen (zoals de klant laten
inloggen met e-pas) zodat men enkel waardevolle reacties overhoudt door
bijvoorbeeld anonieme reacties te vermijden.
|
·
Het systeem zelf mag geen ergernis
opwekken
|
|
·
Telefonische reacties worden nu
doorgeschakeld naar medewerkers die met andere taken belast zijn. In 2006 komen 2 nieuwe medewerkers voor het
opvolgen van reacties.
·
Brieven, fax en telefonische reacties
worden nu zelden geregistreerd.
|
·
Een efficiënt systeem voor het registeren
en opvolgen van reacties die via een ander medium dan het internet bij de VRT
terecht komen, ontbreekt.
|
·
Reacties die via een ander medium dan het
internet bij de VRT terecht komen, moeten in het systeem ingevoerd kunnen
worden
|
·
Het nummer van een kijkerslijn extern
communiceren, kan een aanzuigeffect veroorzaken. Het is beter de telefonische
die nu binnenkomen goed op te volgen.
|
|
CAUSE AND EFFECT ANALYSIS
|
SYSTEM IMPROVEMENT
OBJECTIVES
|
|
Problem or Opportunity
|
Causes and Effects
|
System Objective
|
System Constraint
|
|
·
Moeilijke opvolging: weinig automatisatie
|
·
De reactie komt niet altijd automatisch
bij de juiste persoon terecht.
·
Er is geen automatische methode om
dringende reacties van andere te onderscheiden.
·
Er is geen automatische methode om
klachten, suggesties, felicitaties, vraag of reactie van elkaar te
onderscheiden.
·
Wanneer dezelfde mail binnenkomt via
verschillende postbussen, is het onduidelijk wie de mail opvolgt.
·
Een geautomatiseerd systeem voor
antwoorden met standaardantwoorden ontbreekt.
|
·
Via de keuzes op de invulformulieren op
de verschillende sites, komt de reactie bij de juiste persoon terecht.
·
De werknemer kan de prioriteit van een
probleem aangeven.
·
De klant kan zelf een categorie
aanduiden. De medewerker kan deze nadien nog wijzigen.
·
Bij het doorsturen van reactie, wordt de
verantwoordelijkheid overgedragen. Bij een vraag voor advies, blijft de
oorspronkelijke medewerker verantwoordelijk.
·
De medewerkers kunnen standaardantwoorden
beheren en gebruiken om te antwoorden.
|
·
De klant vindt zijn probleem meestal heel
dringend
|
|
CAUSE AND EFFECT ANALYSIS
|
SYSTEM IMPROVEMENT
OBJECTIVES
|
|
Problem or Opportunity
|
Causes and Effects
|
System Objective
|
System Constraint
|
|
·
Moeilijke opvolging: geen of ontoereikend antwoorden op de
reacties.
|
·
Het behandelen van reacties komt bovenop
andere taken, waardoor er soms de laagste prioriteit aan wordt gegeven.
·
Het aantal reacties vertoont grote pieken
·
Het is niet altijd duidelijk wie
verantwoordelijk is voor het opvolgen van de bepaalde reacties.
·
Het juiste antwoord is niet altijd bekend
bij diegene die reactie opvolgt.
·
Scheldmails worden niet beantwoord.
|
·
Door snel de standaardantwoorden op het
web aan te passen, kunnen veel reacties worden vermeden.
·
Het systeem laat toe dat 2 nieuwe
medewerkers bij externe communicatie piekbelastingen bij bepaalde categorieën
kunnen opvangen.
·
De medewerkers van externe communicatie
beheren de verantwoordelijken voor het opvolgen van de reacties.
·
Er wordt een volledige historiek van de
opvolging bijgehouden (originele en aanvullende reacties, vragen voor advies
en adviezen, verstuurde antwoorden)
·
Reacties zoals scheldmails moeten uit het
systeem kunnen worden verwijderd.
|
·
Het grote aantal reacties blijft voor een
grote werkdruk zorgen.
·
Omdat men het nut om te antwoorden niet
altijd inziet, wordt dit als een last aanzien.
|
CAUSE AND EFFECT ANALYSIS
|
SYSTEM IMPROVEMENT
OBJECTIVES
|
|
Problem or Opportunity
|
Causes and Effects
|
System Objective
|
System Constraint
|
|
·
Moeilijke opvolging: geen controle op de opvolging
|
·
Er is in het algemeen weinig zicht op de
klantenrelaties binnen VRT. De
reactieverwerking hangt af van de bereidheid van de medewerkers.
·
Er is geen registratie van de tijd die de
medewerkers nodig hebben om reacties te verwerken.
·
De kosten van de opvolging zijn niet
gekend.
|
·
Door de reacties en de verwerking
centraal in een database op te slaan, krijgt men een globaal zicht op de
reactieverwerking.
·
De responsetijd moet worden bijgehouden
omdat klachten binnen de 45 dagen moeten beantwoord worden.
|
|
|
·
De reacties bevatten waardevolle
informatie. Analyse van de bestaande
mails is moeilijk.
·
De VRT beantwoordt niet aan de eisen van
het Vlaamse klachtendecreet.
|
·
Niet alle reacties worden bewaard.
·
De reacties worden verspreid bewaard in
de persoonlijke mappen van de medewerker.
·
Er is geen algemeen gebruikte structuur
voor een opslagen reactie. Soms wordt
het soort reactie, het onderwerp, de naam klant en de datum van het antwoord
manueel in de onderwerpregel gezet.
·
De klantgegevens zijn niet eenduidig en
kunnen niet worden herbruikt voor bijvoorbeeld marketing.
|
·
De eenvormige en gestructureerde
registratie in een database, laten zowel een inhoudelijke als een
mathematische analyse toe.
·
Analyse per categorie (klacht,
felicitaties, vraag, suggesties of gewone reactie) is vereist.
·
Externe communicatie vangt automatisch
“signalen” (veel reacties over eenzelfde thema) op
·
De klantengegevens worden het best
gekoppeld aan de klantgegevens van andere e-pas-toepassingen.
·
De klant moet zijn gegevens kunnen
wijzigen of verwijderen.
|
·
Sommige medewerkers kunnen
“gecontroleerd” voelen
·
Het gebruik van persoonlijke gegevens
moet in overeenstemming zijn met de wettelijke bepalingen en het beleid
inzake de bescherming van de persoonlijke levenssfeer.
|
Onderstaande context diagram toont de relaties
tussen het te ontwikkelen systeem en de entiteiten waarmee het systeem in
relatie treedt.
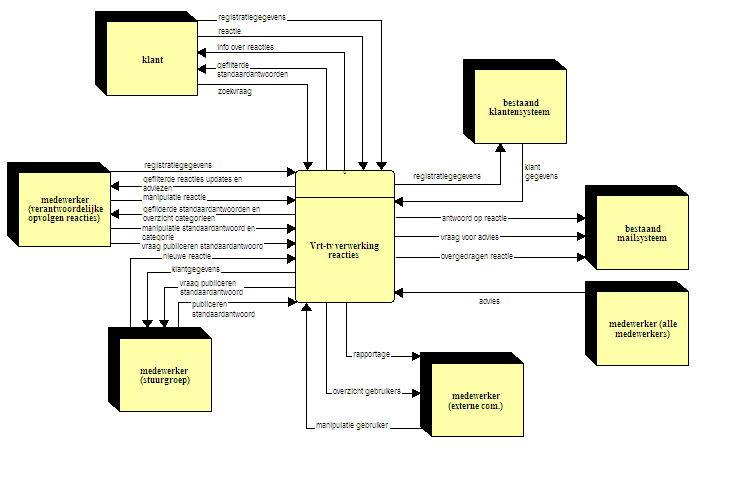
Om de verschillende functies
van het systeem overzichtelijk weer te geven werd een functional decomposition
diagram gemaakt. Hierin wordt per subsysteem aangegeven over welke functionaliteiten
het systeem moet beschikken. De applicatie werd onderverdeeld in twee grote
subsystemen. Het Front-Office enerzijds en het Back-Office anderzijds. Deze
werden op hun beurt verder in subsystemen onderverdeeld. Ook werd aan de taken prioriteiten toegekend.
Er werd een onderscheid gemaakt tussen drie verschillende iteraties. In de
eerste iteratie werden de basisfunctionaliteiten opgenomen. Aanvullende
functionaliteit werd naar de tweede of de derde iteratie verschoven.
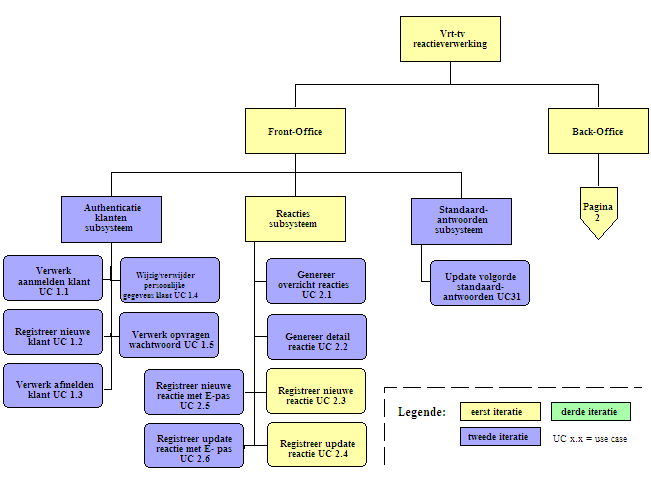
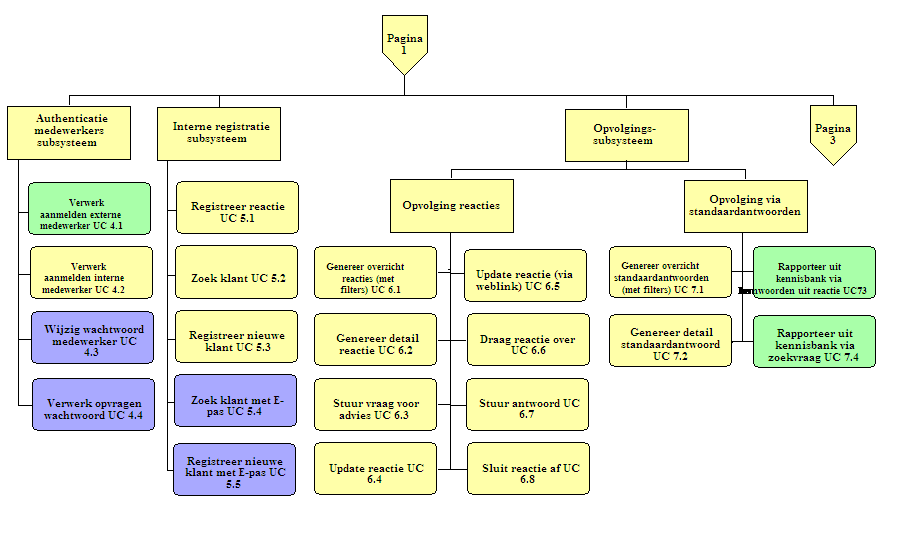
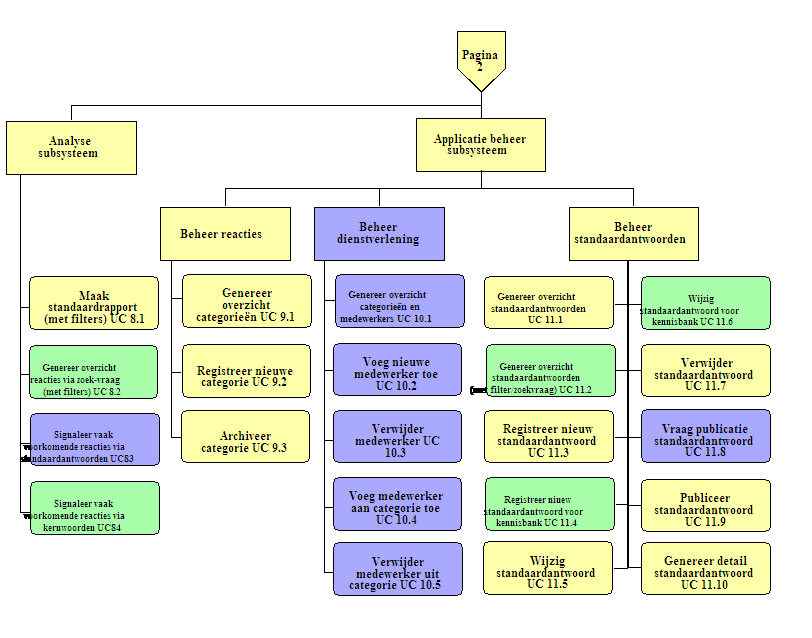
In de
onderstaande tabel werd per functie van het systeem (zie functional
decomposition diagram) een korte beschrijving gemaakt. Hierbij dient te worden
opgemerkt dat een “Medewerker van externe communicatie” automatisch een “Medewerker
van de stuurgroep” is. Een “Medewerker
van de stuurgroep” is op zijn beurt automatisch een “Medewerker die reacties
opvolgt”.
|
Front
Office
|
|
Subsysteem
|
Event (of Use Case)
|
Definitie
|
|
1 Authenticatie klanten
|
|
|
|
|
1.1 Verwerk aanmelden
klant
(TWEEDE ITERATIE)
|
|
|
|
1.2 Registreer nieuwe
klant
(TWEEDE ITERATIE)
|
|
|
|
1.3 Verwerk afmelden
klant
(TWEEDE ITERATIE)
|
|
|
|
1.4 Wijzig /
verwijder persoonlijke gegevens klant
(TWEEDE ITERATIE)
|
|
|
|
1.5 Verwerk opvragen
wachtwoord
(TWEEDE ITERATIE)
|
|
|
2 Reacties
|
|
|
|
|
2.1 Genereer overzicht reacties
(TWEEDE ITERATIE)
|
|
|
|
2.2 Genereer detail reactie
(TWEEDE ITERATIE)
|
|
|
|
2.3 Registreer nieuwe reactie
(EERSTE ITERATIE)
|
|
|
|
2.4 Registreer update reactie
(EERSTE ITERATIE)
|
|
|
|
2.5 Registreer nieuwe reactie met e-pas
(TWEEDE ITERATIE)
|
|
|
|
2.6 Registreer update reactie met e-pas
(TWEEDE ITERATIE)
|
|
|
3 Standaardantwoorden
|
|
|
|
|
3.1 Update volgorde standaardantwoorden
(TWEEDE ITERATIE)
|
|
|
Back
Office
|
|
Subsysteem
|
Event (of Use Case)
|
Definitie
|
|
4 Authenticatie medewerkers
|
|
|
|
|
4.1 Verwerk aanmelden externe medewerker
(DERDE ITERATIE)
|
|
|
|
4.2 Verwerk aanmelden
interne medewerker
(EERSTE ITERATIE)
|
|
|
|
4.3 Wijzig wachtwoord
(DERDE ITERATIE)
|
|
|
|
4.4 Verwerk reset wachtwoord
(DERDE ITERATIE)
|
|
|
5 Interne registratie
|
|
|
|
|
5.1 Registreer reactie
(EERSTE ITERATIE)
|
|
|
|
5.2 Zoek klant
(EERSTE ITERATIE)
|
|
|
|
5.3 Registreer nieuwe klant
(EERSTE ITERATIE)
|
|
|
|
5.4 Zoek klant met e-pas
(TWEEDE ITERATIE)
|
|
|
|
5.5 Registreer nieuwe klant met e-pas
(TWEEDE ITERATIE)
|
|
|
6 Opvolging reacties
|
|
|
|
|
6.1 Genereer overzicht reacties (met filters)
(EERSTE ITERATIE)
|
|
|
|
6.2 Genereer detail reactie
(EERSTE ITERATIE)
|
|
|
|
6.3 Stuur vraag voor advies
(EERSTE ITERATIE)
|
|
|
|
6.4 Update reactie
(EERSTE ITERATIE)
|
|
|
|
6.5 Update reactie (via weblink)
(EERSTE ITERATIE)
|
|
|
|
6.6 Draag reactie over
(EERSTE ITERATIE)
|
|
|
|
6.7 Stuur antwoord
(EERSTE ITERATIE)
|
|
|
|
6.8 Sluit reactie af
(EERSTE ITERATIE)
|
|
|
7 Opvolging via standaardantwoorden
|
|
|
|
|
7.1 Genereer overzicht standaardantwoorden (met filters)
(EERSTE ITERATIE)
|
|
|
|
7.2 Genereer detail standaardantwoord
(EERSTE ITERATIE)
|
|
|
|
7.3 Rapporteer uit kennisbank via kernwoorden uit reactie
(automatisch)
(DERDE ITERATIE)
|
|
|
|
7.4 Rapporteer uit kennisbank via zoekvraag
(DERDE ITERATIE)
|
|
|
8 Analyse
|
|
|
|
|
8.1 Maak standaard- rapport (met filters)
(EERSTE ITERATIE)
|
|
|
|
8.2 Genereer overzicht reacties via zoekvraag (met filters)
(DERDE ITERATIE)
|
|
|
|
8.3 Signaleer vaak voorkomende reacties via faqs
(TWEEDE ITERATIE)
|
|
|
|
8.4 Signaleer vaak voorkomende reacties via kernwoorden
(DERDE ITERATIE)
|
|
|
9 Beheer reacties
|
|
|
|
|
9.1 Genereer overzicht categorieën
(EERSTE ITERATIE)
|
|
|
|
9.2 Registreer nieuwe categorie
(EERSTE ITERATIE)
|
|
|
|
9.3 Archiveer categorie
(EERSTE ITERATIE)
|
|
|
10 Beheer dienstverlening
|
|
|
|
|
10.1 Genereer overzicht categorieën en medewerkers
(TWEEDE ITERATIE)
|
|
|
|
10.2 Voeg nieuwe medewerker toe
(TWEEDE ITERATIE)
|
|
|
|
10.3 Verwijder medewerker
(TWEEDE ITERATIE)
|
|
|
|
10.4 Voeg medewerker aan categorie toe
(TWEEDE ITERATIE)
|
|
|
|
10.5 Verwijder medewerker uit categorie
(TWEEDE ITERATIE)
|
|
|
11 Beheer standaardantwoorden
|
|
|
|
|
11.1 Genereer overzicht standaardantwoorden
(EERSTE ITERATIE)
|
|
|
|
11.2 Genereer overzicht standaardantwoorden (met filter/zoekvraag)
(DERDE ITERATIE)
|
|
|
|
11.3 Registreer nieuw standaardantwoord
(EERSTE ITERATIE)
|
|
|
|
11.4 Registreer nieuw standaardantwoord voor kennisbank
(DERDE ITERATIE)
|
|
|
|
11.5 Wijzig standaardantwoord
(EERSTE ITERATIE)
|
|
|
|
11.6 Wijzig standaardantwoord voor kennisbank
(DERDE ITERATIE)
|
|
|
|
11.7 Verwijder standaardantwoord
(EERSTE ITERATIE)
|
|
|
|
11.8 Vraag publicatie standaardantwoord
(TWEEDE ITERATIE)
|
|
|
|
11.9 Publiceer standaardantwoord
(EERSTE ITERATIE)
|
|
|
|
11.10 Genereer detail standaardantwoord.
(EERSTE ITERATIE)
|
|
De volgende
tabel geeft een overzicht van de events
die binnen de applicatie kunnen optreden en de antwoorden die het systeem op de
events dient te geven. Hierbij dient te worden opgemerkt dat een “Medewerker
van externe communicatie” automatisch een “Medewerker van de stuurgroep”
is. Een “Medewerker van de stuurgroep”
is op zijn beurt automatisch een “Medewerker die reacties opvolgt”.
|
Event Response
List / Front Office / Authenticatie
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Klant
|
1.1 Verwerk aanmelden klant
|
|
Toon beginscherm of foutboodschap
|
Klant
|
|
Klant
|
1.2 Registreer nieuwe klant
|
NIEUWE KLANT
|
Toon beginscherm
(Stuur email met paswoord)
|
Klant
|
|
Klant
|
1.3 Verwerk afmelden klant
|
LOGOUT-REQUEST
KLANT
|
Toon laatst bezochte site
|
Klant
|
|
Klant
|
1.4 Wijzig / verwijder persoonlijke gegevens klant
|
UPDATE PERSOONLIJKE GEGEVENS
|
Toon update persoonlijke gegevens
|
Klant
|
|
Klant
|
1.5 Verwerk opvragen wachtwoord
|
VRAAG VERGETEN PASWOORD KLANT
|
Toon bevestiging verstuurde email
(Stuur email met paswoord)
|
Klant
|
|
Event
Response List / Front Office / Reactie
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Klant
|
2.1 Genereer overzicht reacties
|
|
Genereer overzicht reacties
|
Klant
|
|
Klant
|
2.2 Genereer detail reactie
|
VRAAG DETAIL REACTIE
|
Genereer detail reactie
|
Klant
|
|
Klant
|
2.3 Registreer nieuwe reactie
|
NIEUWE REACTIE
|
Toon bevestiging geregistreerde reactie
|
Klant
|
|
Klant
|
2.4 Registreer update reactie
|
UPDATE REACTIE
|
Toon bevestiging geupdate reactie
|
Klant
|
|
Klant
|
2.5 Registreer nieuwe reactie met e-pas
|
NIEUWE REACTIE
|
Toon bevestiging geregistreerde reactie
|
Klant
|
|
Klant
|
2.6 Registreer update reactie met e-pas
|
UPDATE REACTIE
|
Toon bevestiging geupdate reactie
|
Klant
|
|
Event Response
List / Front Office / Standaardantwoorden
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Klant
|
3.1 Update volgorde standaardantwoorden
|
|
Toon nieuwe volgorde van de standaardantwoorden
|
Klant
|
|
Event Response
List / Back Office / Authenticatie
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Medewerker
(extern)
|
4.1 Verwerk aanmelden externe medewerker
|
|
Toon beginscherm of foutboodschap
|
Medewerker
(extern)
|
|
Medewerker
(intern)
|
4.2 Verwerk aanmelden
interne medewerker
|
|
Toon beginscherm of foutboodschap
|
Medewerker
(intern)
|
|
Medewerker
|
4.3 Wijzig wachtwoord
|
UPDATE WACHTWOORD MEDEWERKER
|
Toon bevestiging wijziging wachtwoord of foutboodschap
|
Medewerker
|
|
Medewerker
|
4.4 Verwerk opvragen wachtwoord
|
VRAAG VERGETEN PASWOORD MEDEWERKER
|
Stuur email met paswoord
|
Medewerker
|
|
Event Response
List / Back Office / Interne registratie
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Medewerker
(stuurgroep)
|
5.1 Registreer reactie
|
|
Toon bevestiging geregistreerde reactie
|
Medewerker
(stuurgroep)
|
|
Medewerker
(stuurgroep)
|
5.2 Zoek klant
|
|
Toon nieuwe reactie met ingevulde klantgegevens
|
Medewerker
(stuurgroep)
|
|
Medewerker
(stuurgroep)
|
5.3 Registreer nieuwe klant
|
|
Toon nieuwe reactie met ingevulde klantgegevens
|
Medewerker
(stuurgroep)
|
|
Medewerker
(stuurgroep)
|
5.4 Zoek klant met e-pas
|
|
Toon nieuwe reactie met ingevulde klantgegevens
|
Medewerker
(stuurgroep)
|
|
Medewerker
(stuurgroep)
|
5.5 Registreer nieuwe klant met e-pas
|
|
Toon nieuwe reactie met ingevulde klantgegevens
|
Medewerker
(stuurgroep)
|
|
Event Response List / Back Office / Opvolging reacties
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Medewerker
|
6.1 Genereer overzicht
reacties (met filters)
|
|
Toon overzicht gefilterde
reacties
|
Medewerker
|
|
Medewerker
|
6.2 Genereer detail reactie
|
VRAAG DETAIL REACTIE
|
Genereer detail reactie met
bijhorende standaardantwoorden
|
Medewerker
|
|
Medewerker
|
6.3 Stuur vraag voor advies
|
VRAAG VOOR ADVIES
|
- mail vraag voor advies
- als de geadresseerde ook
met het systeem werkt, wordt dit enkel in het systeem geregistreerd
|
- Bestaand mailsysteem
- Medewerker
|
|
Medewerker
|
6.4 Update reactie
|
UPDATE REACTIE
|
Toon update in de
detailweergave van de reactie
|
Medewerker
|
|
Elke medewerker
|
6.5 Update reactie (via
weblink)
|
OPVRAGEN WEBLINK
|
Toon bevestiging
|
Elke medewerker
|
|
Medewerker
|
6.6 Draag reactie over
|
OVER TE DRAGEN REACTIE
|
- mail over te dragen
reactie
- als de geadresseerde ook
met het systeem werkt, wordt dit enkel in het systeem geregistreerd
|
- Bestaand mailsysteem
- Medewerker
|
|
Medewerker
|
6.7 Stuur antwoord
|
ANTWOORD VOOR KLANT
|
Mail antwoord naar de klant
|
Bestaand mailsysteem
|
|
Medewerker
|
6.8 Sluit reactie af
|
VRAAG VERWIJDEREN REACTIE
|
Toon overzicht gefilterde
reacties
|
Medewerker
|
|
Event
Response List / Back Office / Opvolging standaardantwoorden
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Medewerker
|
7.1 Genereer overzicht standaardantwoorden (met filters)
|
|
Toon overzicht standaardantwoorden voor de medewerker
|
Medewerker
|
|
Medewerker
|
7.2 Genereer detail standaardantwoord
|
VRAAG DETAIL STANDAARDANTWOORD
|
Toon detail standaardantwoord
|
Medewerker
|
|
Medewerker
|
7.3 Rapporteer uit kennisbank via kernwoorden uit reactie
(automatisch)
|
|
Toon overzicht standaardantwoorden voor reactie
|
Medewerker
|
|
Medewerker
|
7.4 Rapporteer uit kennisbank via zoekvraag
|
|
Genereer overzicht standaardantwoorden
|
Medewerker
|
|
Event
Response List / Back Office / Analyse
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Medewerker
(externe com.)
|
8.1 Maak standaard- rapport (met filters)
|
|
Toon rapport
|
Medewerker
(externe com.)
|
|
Medewerker
(externe com.)
|
8.2 Genereer overzicht reacties via zoekvraag (met filters)
|
ZOEKVRAAG IN REACTIES
|
Toon overzicht reacties
|
Medewerker
(externe com.)
|
|
Klant / Medewerker
|
8.3 Signaleer vaak voorkomende reacties via faqs
|
AANKLIKKEN STANDAARDANTWOORD of
VERSTUREN STANDAARDANTWOORD
|
Toon verwittiging in overzicht reacties
|
Medewerker
(externe com.)
|
|
Klant / Medewerker
|
8.4 Signaleer vaak voorkomende reacties via kernwoorden
|
NIEUWE REACTIE
|
Toon verwittiging in overzicht reacties
|
Medewerker
(externe com.)
|
|
Event
Response List / Back Office / Beheer reacties
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Medewerker
|
9.1 Genereer overzicht categorieën
|
|
Toon overzicht categorieën
|
Medewerker
|
|
Medewerker
|
9.2 Registreer nieuwe categorie
|
|
Toon overzicht categorieën
|
Medewerker
|
|
Medewerker
|
9.3 Archiveer categorie
|
VRAAG VERWIJDEEREN CATEGORIE
|
Toon overzicht categorieën
|
Medewerker
|
|
Event Response List / Back Office / Beheer dienstverlening
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Medewerker
(externe com.)
|
10.1 Genereer overzicht medewerkers
|
|
Toon overzicht medewerkers
|
Medewerker
(externe com.)
|
|
Medewerker
(externe com.)
|
10.2 Voeg nieuwe medewerker toe
|
|
Toon overzicht medewerkers
|
Medewerker
(externe com.)
|
|
Medewerker
(externe com.)
|
10.3 Verwijder medewerker
|
VRAAG VERWIJDEREN MEDEWERKER
|
Toon overzicht medewerkers
|
Medewerker
(externe com.)
|
|
Medewerker
(externe com.)
|
10.4 Voeg medewerker aan categorie toe
|
VRAAG NIEUWE MEDEWERKER VOOR CATEGORIE
|
Toon overzicht medewerkers
|
Medewerker
(externe com.)
|
|
Medewerker
(externe com.)
|
10.5 Verwijder medewerker uit categorie
|
VRAAG VERWIJDEREN MEDEWERKER VOOR CATEGORIE
|
Toon overzicht medewerkers
|
Medewerker
(externe com.)
|
|
Event
Response List / Back Office / Beheer standaardantwoorden
|
|
Actor
|
Event (of Use Case)
|
Trigger(s)
|
Response(s)
|
Destination
|
|
Medewerker
|
11.1 Genereer overzicht standaardantwoorden
|
|
Toon overzicht standaardantwoorden in een mappenstructuur voor de
medewerker
|
Medewerker
|
|
Medewerker
|
11.2 Genereer overzicht standaardantwoorden (met zoekvraag)
|
|
Toon overzicht standaardantwoorden in een mappenstructuur voor de
medewerker
|
Medewerker
|
|
Medewerker
|
11.3 Registreer nieuw standaardantwoord
|
NIEUW STANDAARDANTWOORD
|
Toon overzicht standaardantwoorden in een mappenstructuur voor de
medewerker
|
Medewerker
|
|
Medewerker
|
11.4 Registreer nieuw standaardantwoord voor kennisbank
|
NIEUW STANDAARDANTWOORD MET KERNWOORDEN
|
Toon overzicht standaardantwoorden in een mappenstructuur voor de
medewerker
|
Medewerker
|
|
Medewerker
|
11.5 Wijzig standaardantwoord
|
VRAAG WIJZIGEN STANDAARDANTWOORD
|
Toon overzicht standaardantwoorden in een mappenstructuur voor de
medewerker
|
Medewerker
|
|
Medewerker
|
11.6 Wijzig standaardantwoord voor kennisbank
|
VRAAG WIJZIGEN STANDAARDANTWOORD
|
Toon overzicht standaardantwoorden in een mappenstructuur voor de
medewerker
|
Medewerker
|
|
Medewerker
|
11.7 Verwijder standaardantwoord
|
|
Toon overzicht standaardantwoorden in een mappenstructuur voor de
medewerker
|
Medewerker
|
|
Medewerker
|
11.8 Vraag publicatie standaardantwoord
|
|
Toon bevestiging verstuurd verzoek
|
Medewerker
|
|
Medewerker
(Stuurgroep)
|
11.9 Publiceer standaardantwoord
|
|
Toon overzicht standaardantwoorden in een mappenstructuur voor de
medewerker
|
Medewerker
(Stuurgroep)
|
|
Medewerker
|
11.10 Genereer detail standaardantwoord
|
VRAAG DETAIL STANDAARDANTWOORD
|
Toon detail standaardantwoord
|
Medewerker
|
Het
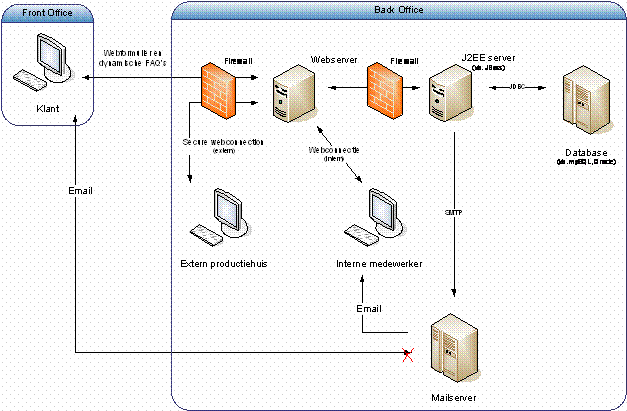
onderstaande diagram geeft op een hoog niveau een beeld van de
systeemarchitectuur die werd voorgesteld aan de klant. Er werd uitgegaan van
een applicatie die in vijf lagen wordt opgebouwd (viewlaag, applicatielaag,
businesslaag, data acces laag en databanklaag) en die via een browser voor de
gebruikers (klanten en medewerkers van VRT) toegankelijk is. Het platform
waarop de applicatie wordt ontwikkeld is het J(2)EE platform.
Dit model
werd in de volgende fases van het project verder verfijnd en geconcretiseerd.
De analyse van
de vereisten (interviews, sampling van documenten en studie van bestaande
systemen) en de deliverables van deze fase (FDD, Context diagram, definitie van
de processen en de event response-lijst) vormen de basis voor het logische
ontwerp, de beslissingsanalyse en het fysieke ontwerp.
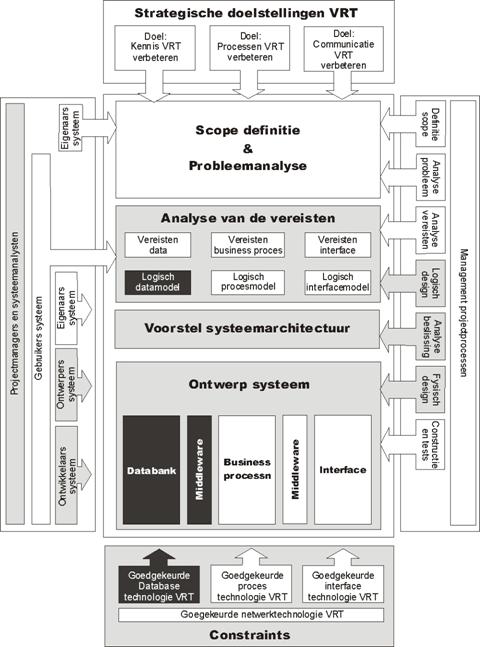
We hebben deze
fases gelijktijdig op twee manieren benaderd: enerzijds vanuit de proces-kant,
anderzijds vanuit de data-kant. Terwijl
voor de proces-kant onder meer de use-cases werden uitgeschreven, hebben we
voor data-kant een aantal logische ERD-modellen gemaakt. Naarmate de versies van de ERD’s concreter
werden, begon dit sterk aan te sluiten bij het domein-model en het OO-ontwerp
van de businesslaag.
Om de
persistentielaag en de businesslaag met elkaar te koppelen, hebben we al vrij
snel beslist Hibernate te gebruiken. Dit
object-relational-mapping (ORM) framework biedt enkele belangrijke voordelen:
·
Association, inheritance, polymorphism, composition en
collections in de OO-wereld
kunnen eenvoudig worden gemapt naar de relationele wereld met XML-files.
·
Proxy-pattern: Welke properties van een klasse uit de
database worden opgehaald, kan dynamisch of via de Hibernate-queries worden bepaald.
·
Optimatisatie
van de caching: veelgebruikte objecten
moeten niet telkens uit de database worden gehaald.
·
Uitbreidbaarheid
bij het gebruik van verschillende databases via de Java Transaction API (JTA).
Deze voordelen
zijn vooral belangrijk om de applicatie schaalbaar te maken en te optimaliseren
voor het grote aantal gebruikers en reacties (250.000 per jaar). Om die zware belasting van de server de baas
te kunnen, zijn we vertrokken van het principe het geheugengebruik op de server
zo veel mogelijk te beperken. In de
applicatie zelf wordt zo weinig mogelijk gecached. Enkel de elementen die echt nodig zijn,
worden bijvoorbeeld in de sessie van de web-gebruiker bewaard. Door zo veel mogelijk de database aan te
spreken doorheen de lagen van de applicatie, kunnen we optimaal gebruik maken
van de strategieën in Hibernate.
De database
werd uiteindelijk geïmplementeerd in MySQL4.1 .
Vanuit de database hebben we Hibernate-XML-configuratie-files en
Java-code laten genereren. De MyEclipse
plugin voor de Eclipse Integrated Development Environment (IDE) was daarbij een grote hulp. De XML-files moesten echter altijd manueel
worden aangepast voor meer gecompliceerde configuraties (lazy-fetching-technieken,
correcte naamgeving, inheritance-strategieën,…). Maar ook de gegeneerde Java-code moest steeds
worden ingepast in de bestaande OO-modellen.
We hebben
in totaal een zestal versies van het logische ERD gemaakt. Onderstaande drie diagrammen geven een beeld
van de evolutie.
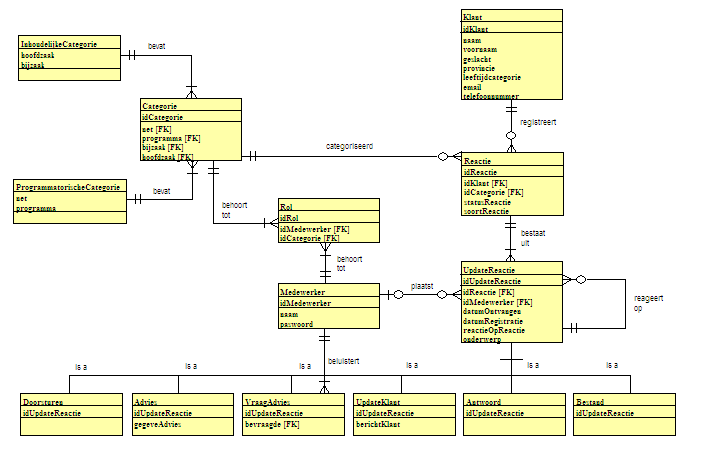

Dit model is een uitbreiding van de oorspronkelijke sneuvelversie. De attributen van elke tabel zijn aangevuld
aan de hand van de info uit de interviews.
Omdat we de hele applicatie in het Engels hebben gemaakt, is ook het ERD
in het Engels vertaald. De belangrijkste
andere wijzigingen zijn:
·
De
gegevens van de klant zijn sterk uitgebreid.
In een tweede iteratie zou het door deze uitbreiding eenvoudiger worden
de data te koppelen met het bestaande e-pas-systeem van de VRT.
·
De
oorspronkelijke boodschap en titel van een reactie worden nu in de reactie zelf
bijgehouden i.p.v. in een aparte update (normalisatie).
·
Er
wordt een type aan de reactie gekoppeld.
Dit is een uitdrukkelijke wens van VRT.
De reacties moeten kunnen worden opgedeeld in felicitatie, vraag,
reactie, suggestie en klacht.
·
Voor
een maximale flexibiliteit is gekozen de categorieën te groeperen in één tabel. Een link
met de parentCategory zorgt voor een hiërarchische structuur. Deze boomstructuur vormt de basis voor de
rechten van de werknemers, de indeling van de reacties en de
indeling van de faq’s. De categorieën
zijn een soort vervanging van de generieke postbussen van het huidige systeem (blokken@vrt.be, tvjournaal@vrt.be,… ).
·
Via
de koppeltabel “topic” kan een reactie gelinkt worden met één of meerdere
“keywords” (derde iteratie). Zo kunnen
de reacties thematisch worden opgedeeld.
Deze opdeling is vooral belangrijk voor de analyse van de reacties. Typisch aan een TV-programma is dat elk
programma zijn eigen specifieke thema’s heeft.
Mensen reageren bijvoorbeeld helemaal anders op een spelprogramma dan op
het journaal. De thema’s moeten ook vlot
aanpasbaar zijn. Een bepaalde
gebeurtenis kan bijvoorbeeld een golf van reacties veroorzaken. Vaste sleutelwoorden voor alle categorieën en
voor een groot aantal gebruikers (decentrale afhandeling van de reacties) zijn
daarom moeilijk bruikbaar. Per categorie
zullen dus specifieke sleutelwoorden worden gebruikt voor de analyse van de
reacties.
·
De
standaardantwoorden zijn aan het model toegevoegd. Deze bevat ook attributen over een eventuele
publicatie op het internet. Niet gepubliceerde
faq kunnen enkel in de applicatie gebruikt worden om te antwoorden op reacties.
·
De
rol van een medewerker is losgekoppeld van de rechten die hij/zij op
categorieën heeft. De rol bepaalt de
mogelijkheden van een gebruiker binnen de applicatie zoals beschreven in het context diagram (zie hoofdstuk 2.3.3).
·
De
gegevens van de medewerker zijn uitgebreid met een automatische handtekening
(gebruikt bij versturen van antwoorden) en een email-adres (binnen de
applicatie gebruikt als login en dus als unieke identificatie van de
medewerker).
·
Een
belangrijke structurele wijziging bij de “updates” is dat “requestAdvice” en
“forward” nu gelinkt zijn met een categorie i.p.v. met een medewerker. Hierdoor kunnen reacties eenvoudiger worden
beheerd bij bijvoorbeeld ziekte of vakantie van een medewerker. Het blijft echter ook mogelijk deze updates
per email te richten aan personen die geen login of paswoord hebben voor het
systeem.
·
Verder
zijn de updates “read” (duidt aan dat een nieuwe of gewijzigde reactie is
gelezen) en “update employee” toegevoegd.
“bestand” is geschrapt om problemen met het uploaden van bestanden te
vermijden (virussen, grootte van de bestanden,…).
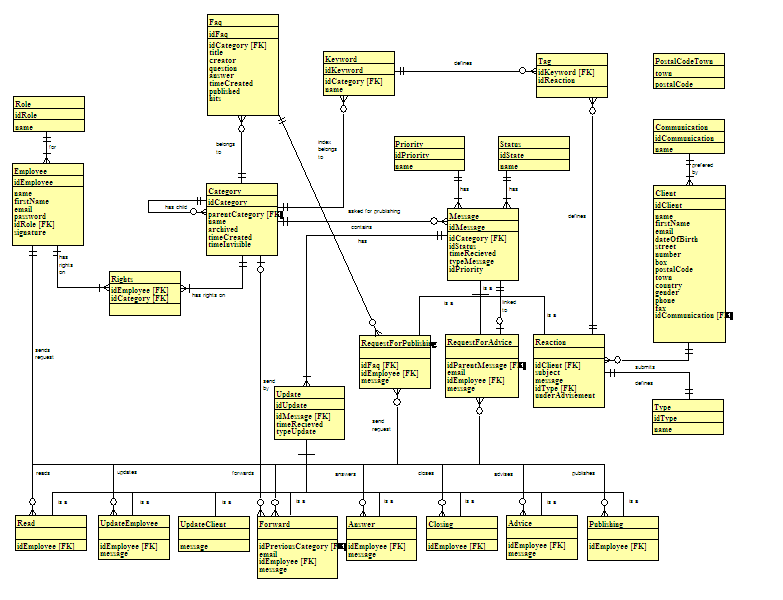
·
Voor
een maximale flexibiliteit wordt het begrip “message” in het model
opgenomen. Reacties van de kijkers zijn
uiteraard een soort boodschap. Maar ook
andere soorten boodschappen kunnen nu op een eenvoudige manier worden
toegevoegd aan de applicatie:
Een “requestForAdvice” als aparte
boodschap lost een belangrijk probleem met de rechten op. Een vraag voor advies moet onder meer kunnen
gericht worden aan een andere categorie (bv. een vraag over een boodschap in de
categorie “één” aan de categorie “blokken”).
Maar een medewerker aan wie de vraag gericht is, heeft niet noodzakelijk
rechten op de oorspronkelijke boodschap (een medewerker die de categorie
“blokken” beheert heeft niet noodzakelijk rechten op de categorie “één”). In het vorige model zou je voor het bepalen
van rechten op een boodschap niet alleen de categorie moeten bekijken. Je zou ook de vraag voor advies-updates
moeten controleren. Het is duidelijk dat
dit een complexe en onnodige stap is.
Zeker bij het opvragen van een overzicht van boodschappen zou dit een
zware extra belasting zijn van de server.
In dit model is een vraag voor advies een nieuwe boodschap. Dit is een stuk eenvoudiger voor het bepalen van
rechten. Via het attribuut “message” in
de tabel “requestForAdvice” kan een gebruiker eenvoudig toegang krijgen tot de
oorspronkelijke boodschap.
Een “requestForPublishing” als aparte
boodschap kan gebruikt worden om een vraag voor publicatie van een faq te
richten aan dezelfde of een andere categorie.
Iemand met de juiste rol kan dan de faq publiceren.
·
Er
zijn twee nieuwe updates. Een boodschap
moet kunnen afgesloten worden zonder de klant te beantwoorden (zie
requirements) met een “close”-update.
Het publiceren van een faq wordt in “requestForPublishing”-boodschap
bijgehouden via een “publishing”-update.
·
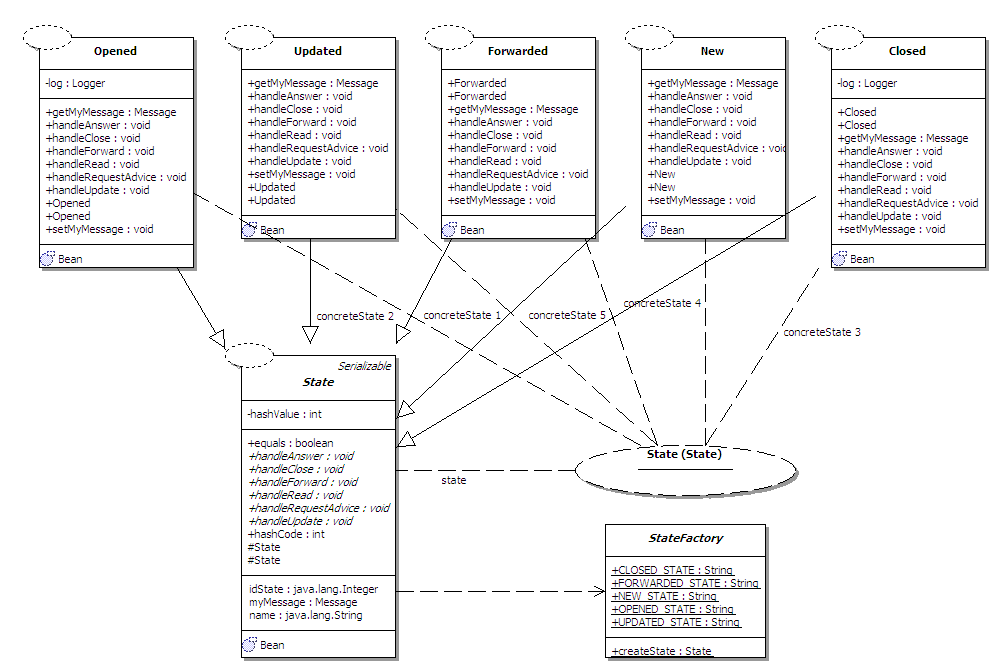
“State”
en “Priority” zijn kleinere property-tabellen maar moeten volgens de
normalisatieregels worden afgezonderd.
Vooral bij de status van een reactie (vb. gesloten, open, doorgestuurd,
geupdate of gesloten) is dit belangrijk.
In het OO-model zal hier namelijk het state-pattern voor worden
gebruikt. Zoals verder in dit verslag
zal blijken, kan Hibernate van die ene tabel een mooie mapping maken naar de
object-wereld.
De prioriteit bepaalt het belang van reactie
(vb. laag, normaal, hoog).
·
Het
door de klant verkozen communicatiemiddel (vb. email, telefoon, fax of brief)
wordt bijgehouden in de hulptabel “Communication”.
Om niet
eindeloos modellen te blijven maken en omdat op dat ogenblik het OO-ontwerp
stilaan vaste vorm begon te krijgen, hebben we op dit punt besloten de database
onmiddellijk in mySQL te implementeren en te combineren met Hibernate. Verdere aanpassingen hebben we dan ook onmiddellijk
op de database zelf gedaan.
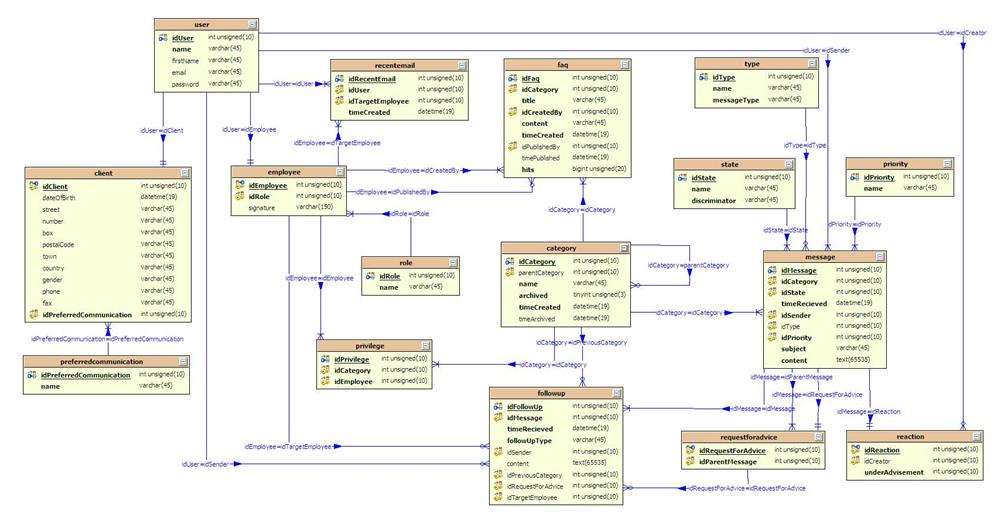
Bovenstaand
ERD-model geeft een beeld van de uiteindelijke implementatie. De logische modellen bleken ook in de
praktijk te werken. Enkel de tabellen
voor de eerste iteratie van de applicatie werden in de fysieke databank
uitgewerkt. Wijzigingen hebben dikwijls
te maken met de eigenlijke implementatie en Hibernate:
·
Gezamelijke
eigenschappen van “client” en “employee” zijn gegroepeerd in de tabel
“user”. Tussen de tabellen bestaat dus
een “is a”-relatie die Hibernate vertaalt naar de object-wereld (zie hoofdstuk
over Hibernate). Ook het paswoord is een
gezamenlijk attribuut. Dit heeft te
maken met de tweede iteratie waarbij de klanten gebruikt kunnen maken van e-pas
en dus een paswoord nodig hebben.
·
De
tabel “right” noemt nu “privilege”en de tabel “update” “followup”. Na wat zoekwerk op een exception in Hibernate
bleken “right” en “update” reserved keywords van MySQL te zijn. De Hibernate-query-taal (zie hoofdstuk over
Hibernate) hield hier geen rekening mee bij de automatische vertaling naar de
SQL-query-taal. Redesign van alle lagen
van de applicatie was de beste oplossing.
·
Wanneer
Hibernate wordt gebruikt met een nieuw ontworpen database, wordt aangeraden
elke tabel een eigen unieke primaire sleutel te geven. Dit geldt dus ook voor koppeltabellen als
“privilege” en de “is a”-relaties. Bij
deze laatste zal Hibernate het beheer van de sleutels voor zich nemen. Dat wil zeggen dat wanneer bijvoorbeeld een nieuwe
klant wordt opgeslagen, er in de tabel “user” en in de tabel “client” records
worden aangemaakt met dezelfde primaire sleutel.
·
De
tabel “recentemail” is toegevoegd.
Tijdens het bouwen van de applicatie bleek het nuttig de laatst
gebruikte emailadressen bij te houden.
·
Alle
followup-types zijn in één tabel ondergebracht.
Dit om het aantal koppelingen tussen verschillende tabellen te
verminderen en zo de performantie van de queries te verhogen. Hibernate laat toe een “is a”-relatie binnen
één tabel te definiëren. De
verschillende types worden dan automatisch vertaald naar verschillende klassen
in de business-laag. Dit was de oorspronkelijk
implementatie.
Maar er zijn slechts weinig verschillende
attributen voor de verschillende followups.
Bovendien waren de aparte klassen voor de followups eerder een probleem voor
de view (upcasting) dan een meerwaarde.
Daarom hebben we de aparte klassen laten vallen.
·
Sommige
attributen van een reactie zijn verhuisd naar boodschap. Zo kunnen de properties worden hergebruikt
door andere soorten boodschappen.
·
Bij
een reactie kan de gebruiker die de reactie heeft aangemaakt, worden bewaard. Bij een reactie via het Front-Office is dit
de afzender zelf. Bij een reactie via
het back-office is dit de medewerker die de reactie aanmaakte.
Beschrijving
van alle geïmplementeerde tabellen en hun attributen.
De hiërarchische structuur voor de reacties, faq, rechten voor gebruikers,…
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
IdCategory
|
int(10)
|
Nee
|
|
PK
|
|
parentCategory
|
int(10)
|
Ja
|
NULL
|
FK category.idCategory -
“Parent”-categorie in de boomstructuur
|
|
Name
|
varchar(45)
|
Nee
|
|
Naam van de categorie
|
|
Archived
|
tinyint(3)
|
Nee
|
|
Categorieën mogen niet worden
verwijderd om analyse van de data mogelijk te maken. Om ze voor de rest van de applicatie
onzichtbaar te maken kan een categorie worden gearchiveerd.
|
|
TimeCreated
|
datetime
|
Nee
|
|
Tijdstip waarop de categorie werd
gecreëerd of aangepast.
|
|
timeArchived
|
datetime
|
Ja
|
NULL
|
Tijdstip waarop de categorie werd
gearchiveerd
|
De klanten waar het allemaal om draait J.
Bevat de velden die niet gemeenschappelijk zijn met “User” (“tabel per
subklasse”-mapping met “User”)
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idClient
|
int(10)
|
Nee
|
|
PK – FK
user.idUser – elke client is gelinkt met een user met dezelfde PK
|
|
dateOfBirth
|
Datetime
|
Ja
|
NULL
|
Geboortedatum
|
|
street
|
Varchar(45)
|
Ja
|
Onbekend
|
Straat
|
|
number
|
Varchar(45)
|
Ja
|
Onbekend
|
Nummer
|
|
box
|
Varchar(45)
|
Ja
|
Onbekend
|
Postbus
|
|
postalCode
|
Varchar(45)
|
Ja
|
Onbekend
|
PostCode
|
|
Town
|
Varchar(45)
|
Ja
|
Onbekend
|
Stad
|
|
country
|
Varchar(45)
|
Ja
|
Onbekend
|
Land
|
|
gender
|
Varchar(45)
|
Ja
|
Onbekend
|
Geslacht
|
|
phone
|
Varchar(45)
|
Ja
|
Onbekend
|
Telefoonnummer
|
|
fax
|
Varchar(45)
|
Ja
|
Onbekend
|
Faxnummer
|
|
idPreferredCommunication
|
int(10)
|
Nee
|
|
FK preferredCommunication.
idPreferredCommunication – De wijze waarop de klant wenst
benaderd te worden (vb. email, fax, brief, telefoon,…)
|
De werknemers van VRT en externe bedrijven die de reacties behandelen. Bevat de velden die niet gemeenschappelijk
zijn met “User” (“tabel per subklasse”-mapping met “User”)
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idEmployee
|
int(10)
|
Nee
|
|
PK – FK
user.idUser – elke employee is gelinkt met een user met dezelfde PK
|
|
idRole
|
int(10)
|
Nee
|
|
FK role.idRole – De
rol van een employee bepaalt de mogelijkheden die de werknemer heeft om
bepaalde acties uit te voeren
|
|
signature
|
varchar(150)
|
Ja
|
NULL
|
De automatische handtekening van de
werknemer die wordt gebruikt bij het beantwoorden van boodschappen
|
De standaardantwoorden die gebruikt worden door de werknemers om te
antwoorden en die kunnen geraadpleegd worden door de klanten via het internet.
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idFaq
|
int(10)
|
Nee
|
|
PK
|
|
idCategory
|
int(10)
|
Nee
|
|
FK category.idCategory – De
categorie waartoe de faq behoort
|
|
title
|
varchar(45)
|
Nee
|
|
Titel
|
|
idCreatedBy
|
int(10)
|
Nee
|
|
FK employee.idEmployee – De werknemer die de faq heeft gecreëerd of
aangepast
|
|
content
|
varchar(45)
|
Nee
|
|
De inhoud van de faq
|
|
timeCreated
|
datetime
|
Nee
|
|
Tijdstip waarop de faq werd
gecreëerd of aangepast
|
|
idPublishedBy
|
int(10)
|
Ja
|
NULL
|
FK employee.idEmployee – De werknemer die de faq heeft gepubliceerd
|
|
timePublished
|
datetime
|
Ja
|
NULL
|
Tijdstip waarop de faq is
gepubliceerd
|
|
hits
|
bigint(20)
|
Nee
|
|
Het aantal keer een faq is
aangeklikt. Veel aangeklikte faqs
kunnen hoger in de lijst komen (niet geïmplementeerd)
|
De opvolging van de reactie door werknemers en klanten
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idFollowUp
|
int(10)
|
Nee
|
|
PK
|
|
idMessage
|
int(10)
|
Nee
|
|
FK message.idMessage
– De boodschap waar de follow-up bij hoort
|
|
timeRecieved
|
Datetime
|
Nee
|
|
Tijdstip waarop de follow-up werd
geregistreerd
|
|
followUpType
|
varchar(45)
|
Nee
|
|
Soort follow-up
|
|
idSender
|
int(10)
|
Ja
|
NULL
|
FK user.idUser
– De gebruiker die de boodschap heeft verstuurd
|
|
Content
|
Text
|
Ja
|
NULL
|
De inhoud van de follow-up
|
|
idTargetEmployee
|
varchar(45)
|
Ja
|
NULL
|
FK employee.idEmployee
– De werknemer voor wie een followUp werd gecreëerd (wordt enkel gebruikt als
per mail een boodschap verstuurd werd naar een werknemer die geen login/
paswoord heeft voor het systeem. In de
andere gevallen wordt via de categorieën gewerkt)
|
|
idPreviousCategory
|
int(10)
|
Ja
|
NULL
|
FK category.idCategory
– Oude categorie die bewaard wordt bij het doorsturen van een boodschap naar
een andere categorie.
|
|
idRequestForAdvice
|
int(10)
|
Ja
|
NULL
|
FK requestForAdvice.
idRequestForAdvice
– De vraag voor advies die gekoppeld is aan de follow-up
|
Een boodschap in het systeem (vb. een reactie
van een klant, een vraag voor advies of een vraag voor publicatie van een faq).
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idMessage
|
int(10)
|
Nee
|
|
PK
|
|
idCategory
|
int(10)
|
Nee
|
|
FK category.idCategory – de
categorie waartoe de boodschap behoort
|
|
idState
|
int(10)
|
Nee
|
|
FK state.idState – de
status van de boodschap
|
|
timeRecieved
|
datetime
|
Nee
|
|
Tijdstip waarop de boodschap werd
geregistreerd
|
|
idSender
|
int(10)
|
Nee
|
|
FK user.idUser – de
gebruiker die de boodschap verstuurt
|
|
idType
|
int(10)
|
Ja
|
NULL
|
FK type.idType
– het type boodschap (vb. Felicitatie, klacht,
reactie, vraag, suggestie)
|
|
idPriority
|
int(10)
|
Nee
|
|
FK priority.idPriority
– de prioriteit van de boodschap (vb. laag, gewoon, hoog)
|
|
Subject
|
varchar(45)
|
Nee
|
|
De titel van de boodschap
|
|
Content
|
Text
|
Nee
|
|
De boodschap zelf
|
De wijze waarop de klant wenst gecontacteerd te
worden (vb. via mail, brief, fax of email)
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idPreferredCommunication
|
int(10)
|
Nee
|
|
PK
|
|
name
|
varchar(45)
|
Nee
|
|
De naam van het communicatiemiddel
|
De prioriteit van een boodschap (vb. laag, normaal, hoog)
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idPriority
|
int(10)
|
Nee
|
|
PK
|
|
name
|
varchar(45)
|
Nee
|
|
De naam van de prioriteit
|
Link tussen de categorieën en de werknemers. Elke categorie waar een werknemer rechten op
heeft, heeft een record in privilege.
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idPrivilege
|
int(10)
|
Nee
|
|
PK
|
|
idCategory
|
int(10)
|
Nee
|
|
FK category.idCategory – de
categorie waar de werknemer rechten op heeft
|
|
idEmployee
|
int(10)
|
Nee
|
|
FK employee.idEmployee – de
werknemer die rechten heeft een bepaalde catgeorie
|
Een reactie van een klant. Hij kan
deze zelf invullen via het web of een werknemer kan dit voor de klant doen
(reacties via brief, telefoon of fax). Bevat de velden die niet
gemeenschappelijk zijn met “Message” (“tabel per subklasse”-mapping met
“Message”)
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idReaction
|
int(10)
|
Nee
|
|
PK – FK message.idMessage
– elke reactie is gelinkt met een message met dezelfde PK
|
|
idCreator
|
int(10)
|
Ja
|
0
|
FK user.idUser – de
gebruiker die de reactie heeft gecreëerd.
Als de boodschap door de klant via het web ingevoerd is dit hetzelfde
als de “sender”.
|
|
underAdvisement
|
int(10)
|
Nee
|
|
Inner state die aanduid dat er een
openstaande vraag voor advies is
verstuurd
|
Slaat per gebruiker de laatst medewerkers op waarnaar een email werd
gestuurd.
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idRecentEmail
|
int(10)
|
Nee
|
|
PK
|
|
idUser
|
int(10)
|
Nee
|
|
FK user.idUser – de
gebruiker voor wie de geadresseerden worden bewaard
|
|
idTargetEmployee
|
Int(10)
|
Nee
|
|
FK employee.idEmployee
– de geadresseerd medewerkers
|
|
timeCreated
|
datetime
|
Nee
|
|
Tijdstip waarop de email werd
verstuurd
|
Een vraag voor advies. Bevat de
velden die niet gemeenschappelijk zijn met “Message” (“tabel per
subklasse”-mapping met “Message”)
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idRequestForAdvice
|
int(10)
|
Nee
|
|
PK – FK message.idMessage
– elke request for advice is gelinkt met een message met dezelfde PK
|
|
idParentMessage
|
int(10)
|
Nee
|
|
FK message.idMessage –
geeft toegang tot de oorspronkelijke message.
De gebruiker heeft hiervoor geen rechten op de categorie van de oorspronkelijke
categorie nodig.
|
Bepaalt de mogelijkheden die de werknemer heeft om
bepaalde acties uit te voeren
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idRole
|
int(10)
|
Nee
|
|
PK
|
|
name
|
varchar(45)
|
Nee
|
|
Naam
|
Status van een boodschap (vb. nieuw, geopend, doorgestuurd, ge-update,
gesloten)
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idState
|
int(10)
|
Nee
|
|
PK
|
|
name
|
varchar(45)
|
Nee
|
|
Naam
|
|
discriminator
|
varchar(45)
|
Nee
|
|
DISCRIMATOR: waarde gebruikt door Hibernate
voor het initialiseren van de verschillende afgeleide klassen van “State”
|
Het type boodschap (vb. felicitatie, klacht,
reactie, vraag, suggestie, advies gevraagd)
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idType
|
int(10)
|
Nee
|
|
PK
|
|
name
|
varchar(45)
|
Nee
|
|
Naam
|
|
messageType
|
varchar(45)
|
Nee
|
|
De subklasse van message waarvoor het
type kan gebruikt worden
|
De gebruiker van het systeem.
|
Veld
|
Type
|
Null
|
Standaardwaarde
|
Commentaar
|
|
idUser
|
int(10)
|
Nee
|
|
PK
|
|
name
|
varchar(45)
|
Nee
|
|
Naam
|
|
firstName
|
varchar(45)
|
Ja
|
NULL
|
Voornaam
|
|
email
|
varchar(45)
|
Ja
|
NULL
|
Email
|
|
password
|
varchar(45)
|
Ja
|
NULL
|
Paswoord
|
Het
statement van Hibernate is “de ontwikkelaar verlossen van 95 percent van de
basis data gerelateerde programmeertalen”. Door de combinatie van klassieke
Java klassen met XML omschrijvingen, voorziet Hibernate een object georiënteerd
zicht op een relationele database.
De keuze
van een relationele database is bijna een evidente keuze. Een relationele
database is een ongelofelijk flexibele en robuuste benadering van
datamanagement. Daarnaast kan een relationele database op diverse wijze
benaderd worden, afhankelijk van de toepassing en de gebruikte technologieën.
Relationele
databases voorzien een gestructureerde representatie van de opgeslagen data,
met geavanceerde mogelijkheden om te sorteren, op te zoeken en data te
groeperen.
Daarnaast
werken we in een objectgeoriënteerde omgeving waar de inhoud van een object, het
object overleeft. De staat waarin het object zich bevindt kan opgeslagen
worden. Later kan dan eventueel een object met dezelfde inhoud worden
gecreëerd.
De businesslogica
wordt nooit verwerkt in de database, maar wordt geïmplementeerd in een object georiënteerde
omgeving. Dit laat toe gebruik te maken van concepten als polymorphisme en
inheritance.
Granulariteit
refereert naar de relatieve grootte van de objecten waarmee je werkt. Een Java object kan kleinere objecten
bevatten. Die kunnen op hun beurt
opnieuw kleinere objecten bevatten, enz… De structuur van tabellen en kolommen
in een relationele databank is uiteraard minder flexibel.
In Java
implementeren we overerving met super- en subklassen. De subklassen kunnen bijkomende attributen bijhouden
die op hun beurt persistent moeten worden gemaakt.
Relationele
databases hebben geen notie overerving en kunnen dus geen polymorphische
associaties weergeven.
Java
objecten hebben twee noties van gelijkheid. Een eerste is de identiteit van een object,
wat ongeveer overeenkomt met de geheugenlocatie van het object. Een tweede wordt gedefinieerd door de equals(
) method.
Daartegenover
staat de identiteit in een relationele database die gedefinieerd wordt door de
primaire sleutel.
In een
object georiënteerde omgeving worden associaties gelegd door de referentie van
een object te gebruiken. In de
relationele wereld worden associaties gelegd met foreign keys.
Daarnaast
heeft een associatie in de objectgeoriënteerde wereld een richting. Een object
kan een referentie naar één of meerdere objecten bezitten. Voor een wederzijdse
associatie dienen beide objecten een referentie naar het andere object te bezitten.
In de relationele wereld hebben foreign keys echter geen richting. Een associatie kan door queries in de twee
richtingen worden gebruikt.
In een
object georiënteerde wereld zijn many-to-many
relaties mogelijk. Tabelassociaties hebben een one-to-one of one-to-many relatie.
De meest natuurlijke wijze om objectgeoriënteerde data te benaderen,
wordt dikwijls omschreven als “walking
the object graph”. Je navigeert van een object naar een ander met behulp
van de bestaande associaties.
Het aantal
tabellen dat wordt gekoppeld in een SQL-query, bepaalt de diepte van het object graph waarin je kan navigeren. We moeten dus eerst de gewenste diepte kennen
voor we de data van een object opvragen.
Eén van de
mogelijke oplossingen, om de verschillen tussen een object georiënteerde
programmeertaal en een relationele database op te vangen, is het gebruik van
object/relational mapping (ORM).
Object/relational
mapping is het geautomatiseerd bewaren of opvragen van de objecten, gebruik
makend van metadata die de relaties beschrijft tussen de objecten en de database.
ORM zal dus de representatie van een
object omzetten in de representatie op relationeel niveau en omgekeerd.
Een ORM
oplossing bestaat uit de volgende vier delen:
·
Een
API voor de basis CRUD-operaties (Create, Read, Update en Delete) van de
objecten.
·
Een
taal of API voor het definiëren van queries die refereren naar klassen en
eigenschappen van klassen.
·
Een
mogelijkheid om de mapping in metadata te definiëren.
·
Extra
functionaliteiten voor optimalisatie, lazy fetching (het bepalen van welke data
wordt opgehaald) of dirty checking (het vergelijken van het object en zijn
database-entiteit)
ORM maakt
gebruik van metadata om de mapping te specificeren tussen het object georiënteerde
model en het relationele model. Deze informatie wordt de object/relational mapping metadata genoemd. Binnen Hibernate wordt XML
gebruikt om deze metadata te definiëren. Daardoor zijn ze goed leesbaar en
gemakkelijk te manipuleren door version-control
systems en tekstverwerkers.
Om het
mappen van persistente objecten in metadata naar een relationele database te
verduidelijken nemen we er even de Message.hbm.xml
bij, omdat dit de entiteit is waarrond onze applicatie is opgebouwd.
Het gebruik
van document type declaration (DTD) maakt automatische aanvulling en validatie
mogelijk en laat ook toe standaard waarden te definiëren.
<?xml
version="1.0"?>
<!DOCTYPE hibernate-mapping
PUBLIC
"-//Hibernate/Hibernate Mapping DTD 2.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-2.0.dtd"
>
·
Entity en value type
Hibernate
onderscheidt twee type van objecten: objecten van het entity type en objecten van het value
type.
Een object
van het entity type zal zijn eigen
database identiteit hebben in de vorm van een primaire sleutel. Een object
referentie naar dit object zal worden opgeslagen als referentie in de database
(foreign key). Een entiteit heeft een
eigen levenscyclus en staat los van elk ander entiteit.
Een object
van het value type heeft geen
database identiteit. Het object behoort tot een entiteit en zijn staat wordt
opgeslagen in de rij van de bezittende entiteit (met uitsluiting van collections, die ook als value types worden beschouwd). De
levenscyclus van deze objecten is gekoppeld aan de cyclus van de entiteit
waarbij het object hoort.
Als we naar
onderstaand voorbeeld kijken, onderscheiden we het object Message waarin we een
referentie leggen naar een state-, category-, priority-, type- en sender-object
die als entity type gedefinieerd
zijn. Daarnaast zijn timeRecieved-, subject-, content- en underAdvisement- en content-object
van het value type.
FollowUps
die bij de initiële message horen, worden in een collectie (Set) opgenomen.
<hibernate-mapping package="be.vrt.cr.message.model">
<class name="Message" table="message"
lazy="true">
<id
name="idMessage" column="idMessage"
type="java.lang.Integer">
<generator
class="increment"/>
</id>
<property
name="timeRecieved" column="timeRecieved"
type="java.util.Date"
not-null="true" />
<property
name="subject" column="subject"
type="java.lang.String"
not-null="true" />
<property
name="content" column="content"
type="java.lang.String"
not-null="true" />
<many-to-one
name="state" column="idState"
class="be.vrt.cr.message.model.state.State"
not-null="true"
/>
<many-to-one
name="category" column="idCategory"
class="be.vrt.cr.category.model.Category" not-null="true" />
<many-to-one
name="priority" column="idPriority"
class="Priority"
not-null="true" />
<many-to-one
name="type" column="idType" class="Type"
/>
<many-to-one
name="sender" column="idSender"
class="be.vrt.cr.user.model.User"
not-null="true" />
<set name="followUps"
lazy="true" order-by="timeRecieved" >
<key
column="idMessage"/>
<one-to-many
class="be.vrt.cr.message.model.FollowUp"/>
</set>
<joined-subclass name="Reaction"
table="reaction">
<key
column="idReaction"/>
<property
name="underAdvisement" column="underAdvisement"
type="java.lang.Short" not-null="true" />
<many-to-one
name="creator" column="idCreator" class="be.vrt.cr.user.model.User"
/>
</joined-subclass>
<joined-subclass name="RequestForAdvice"
table="requestForAdvice">
<key
column="idRequestForAdvice"/>
<many-to-one
name="parentMessage" column="idParentMessage"
class="Message"
not-null="true" />
</joined-subclass>
</class>
</hibernate-mapping>
·
Mapping class inheritance
In
bovenstaand voorbeeld wordt gebruik gemaakt van één van de drie strategieën
voor het vertalen van overerving naar een relationeel model. Hier wordt het
principe van een tabel per subklasse toegepast. “Message” is de moedertabel en de tabellen “reactie”
en “requestForAdvice” hebben een “is a”-relatie
met “message”.
Het
voordeel is dat het relationeel model volledig is genormaliseerd is, het nadeel
is dat voor het opvragen van een “reactie” een koppeling met de tabel “message”
nodig is. Dit is in onze applicatie
echter geen probleem. Bij het opvragen
van de details van een reactie moeten de gegevens van slechts één record worden
opgehaald uit de tabel “message” en de tabel “reaction”. Bij het opvragen van het overzicht van de
boodschappen worden enkel properties geladen uit de tabel “message”.
Een ander
mapping-principe dat we hebben toegepast is de tabel per klasse
hiërarchie. Hierbij worden de properties
van de superklasse en van alle subklassen in één tabel ondergebracht. Het voordeel is een betere performantie door
het vermijden van koppelingen tussen tabellen, het nadeel is dat één tabel properties
van verschillende klassen bevat en null-values moeten toegelaten worden.
Voor de
implementatie van het State-pattern (zie hoofdstuk 4.5.2) was deze optie
ideaal. De verschillende subklassen
bevatten immers geen verschillende properties (enkel verschillend gedrag). Een speciale kolom “discriminator” bepaalt
tot welke subklasse de records in de database behoren.
<hibernate-mapping
package="be.vrt.cr.message.model.state">
<class name="State" table="state"
lazy="true">
<id name="idState" column="idState"
type="java.lang.Integer">
<generator class="increment"/>
</id>
<discriminator column="discriminator"
type="java.lang.String" not-null="true"/>
<property name="name" column="name"
type="java.lang.String"
not-null="true" />
<subclass name="New" discriminator-value="N"/>
<subclass name="Opened"
discriminator-value="O"/>
<subclass name="Updated"
discriminator-value="U"/>
<subclass name="Forwarded"
discriminator-value="F"/>
<subclass name="Closed"
discriminator-value="C"/>
</class>
</hibernate-mapping>
Eenmaal de
mapping is geconfigureerd, kunnen we de database benaderen voor het bewaren en
ophalen van objecten.
Voor het
benaderen van een database wordt gebruik gemaakt van een persistence manager.
De persistence
manager is een API die de volgende functionaliteiten biedt:
·
Basis CRUD operaties
·
Uitvoering van queries
·
Controle over transacties
·
Management van de
transaction-level cache
De
interface voor persistence management, waar alles om draait bij Hibernate, is
de Session interface.
In onze
toepassing wordt een Session object aangeboden door een HibernateSessionFactory
die eenmalig een SessionFactory object creëert. Dit SessionFactory object wordt
dan verder doorheen de applicatie gebruikt voor het aanmaken van Session
objecten. De reden is eenvoudig, een SessionFactory is zwaar om aan te maken
terwijl een Session object met weinig middelen gecreëerd kan worden.
Door het
gebruik van het Session object, spreekt men de first-level cache aan van de
two-level cache architecture van Hibernate. In deze cache wordt per sessie (extra)
data bijhouden van de gemaakte queries. Zo worden database connecties vermeden
als een applicatie een object zoekt op identiteit en associaties lazy geladen
worden (zie verder).
Om een
sessie niet open te houden zolang een object gebruikt en gemanipuleerd wordt,
ondergaat het een statuswijziging. Het object gaat van persistent
instance naar detached instance
wanneer de sessie wordt gesloten. Dient
het object zijn wijzigingen op te slaan, dan zal er een nieuw Session- en
Transaction object aangemaakt worden.
Zoals bij
de standaard SQL queries dienen transacties in Hibernate, te voldoen aan het
ACID criterium.
In de
eerste plaats dient een transactie Atomair
te zijn. Alles of niets, als een deel van de transactie fout loopt, loopt heel
de transactie fout. Consistency dient
gewaarborgd te worden door enkel geldige data naar de database weg te schrijven. Met Isolation kunnen transacties simultaan verlopen zonder een impact op elkaar te
hebben. Tot slot mogen de gegevens die
succesvol opgeslagen worden, niet verloren gaan (Durable).
We hebben
in onze applicatie de scope van de sessie meestal beperkt tot de methodes
binnen de Data Access Objects (DAO, objecten die de logica voor het aanspreken
van de databaselaag bevatten). In de
meeste gevallen is scope van de transacties ook gelijk aan de scope van de
sessies. Zo worden de databaseconnecties
zo kort mogelijk gehouden en zal de data in de first-level sessie-cache het
beste overeenkomen met de data in databank.
Het isolation level van de JDBC-connectie (“repeatable read”) zorgt
immers voor de nodige ACID-kenmerken.
We hebben in de
HibernateSessionFactory het Thread-Local pattern geïntegreerd. Een thread is een reeks instructies die tegelijk met andere threads kan
worden uitgevoerd. Het Tread-Local
pattern maakt eenzelfde instantie van een object beschikbaar voor de hele
thread. We gebruiken dit patroon wanneer
een DAO een andere DAO oproept. Zo kan
hetzelfde sessie- en transactie-object worden gebruikt zonder dit te moeten
doorgeven als parameter van een methode.
Voor het
uitvoeren van Queries heeft Hibernate een eigen taal ontwikkeld, de Hibernate
Query Language (HQL). HQL lijkt sterk op
SQL maar baseert zich op objecten.
Als basis
zijn we vertrokken van lazy fetching.
Hierbij wordt een associatie of collectie
pas uit de database opgehaald als daar expliciet om gevraagd wordt. Indien
dit niet het geval is, zal enkel het gevraagde object worden opgehaald. Als men
bijvoorbeeld een Message object opvraagt uit de database, krijgt men enkel het
object zonder de complete graph. Voor een associatie of collectie wordt een proxy-object
geïnitialiseerd. Dit is een soort leeg
vervang-object dat toegang geeft tot de eigenlijke data. Wil je de data van de
proxies gebruiken dan moet de database worden aangesproken.
Dit hebben
we in onderstaand voorbeeld voorkomen door eager
fetching te definiëren op het niveau van de queries. Hiermee kan perfect
worden bepaald welke associaties van een Message uit de database worden
opgevraagd.
public static Message getMessage(int idMessage, User user) throws
MessageException{
Message message = null;
try{
StringBuffer sb = new
StringBuffer("select m from Message m ");
sb.append("join fetch
m.state ");
sb.append("join fetch
m.priority ");
sb.append("join fetch
m.type ");
sb.append("join fetch
m.sender ");
sb.append("join fetch
m.category c ");
sb.append("left join fetch
m.followUps f ");
sb.append("left join fetch
f.sender s ");
sb.append("join c.privileges priv
");
sb.append("where priv.employee = :user
");
sb.append("and m.idMessage = :idMessage");
Session mySession =
HibernateSessionFactory.currentSession();
Transaction tx = mySession.beginTransaction();
Query myQuery = mySession.createQuery(
sb.toString() );
user = (Employee) user;
myQuery.setEntity("user",user);
myQuery.setInteger("idMessage",
idMessage);
List messages = myQuery.list();
tx.commit();
HibernateSessionFactory.closeSession();
if(messages.size()==0){
throw new MessageException("No
messsages found");
}
return message;
}
catch(Exception e){
throw new MessageException("Cannot load the requested message from
the database",e);
}
}
Voor het
ophalen van een Message object voor een bepaalde User, moet men in de where- clausule de identiteit van de
message en de user voor wie deze gegevens bestemd zijn, meegeven. Deze kunnen
dynamisch worden meegegeven via de setEntity( )- en setInteger( )-functies.
Zoals in
het vorige hoofdstuk beschreven, volgen na het verzamelen van de systeemeisen
de fases van het logisch design, de beslissingsanalyse en het fysiek
ontwerp. Dit hoofdstuk beschrijft de
analyse en het ontwerp vanuit de proces-kant.
Het vorige hoofdstuk ging dieper in op de analyse en het ontwerp vanuit
de data-kant. Een wisselwerking tussen
die twee benaderingswijzen en de gelaagde structuur van de applicatie zorgden
uiteindelijk voor een sluitend geheel.
In het
functional decomposition diagram, de definitie van de processen en de event
response-lijst werden de processen in onze applicatie geïdentificeerd. Om een duidelijk beeld te krijgen van exacte
functionaliteit van de applicatie, werden de use-cases verder uitgewerkt aan de
hand een use-case-diagram en de use-case-beschrijvingen. Deze use-case-beschrijvingen werden tenslotte
stuk voor stuk overlopen en goedgekeurd door de klant.
Zoals bij
de data-kant hebben we ook hier vrij snel beslist een framework te gebruiken. Jakarta Struts heeft door zijn grote
populariteit zijn degelijkheid zeker bewezen.
Het laat toe de functionaliteit te modeleren in een voor een
webapplicatie aangepaste MVC-structuur.
Hiervoor wordt een centraal XML-document gebruikt. De MyEclipse-tool kan dit document en dus ook
de functionaliteit visueel voorstellen. De
tool is echter minder handig voor het aanpassen van de XML-file. Het is eenvoudiger de file manueel aan te
passen.
Daarnaast
biedt het uitbreidbare Struts-framework een aantal nuttige functionaliteiten
voor onze applicatie:
·
De
controle van de input van de gebruiker.
Onder het motto “geen rommel in de database, betekent ook geen rommel
uit database”, wordt meestal veel aandacht besteed aan de validatie van de
input. Met Struts en het Jakarta
Validator Framework is validatie op verschillende niveaus van de applicatie
(client- en serverside) eenvoudig.
·
Het
ondersteunen van verschillende talen: De
applicatie zelf is in het Engels gebouwd.
Enkel de view is in het Nederlands.
Struts kan dit eenvoudig van elkaar scheiden en eventueel andere talen
implementeren.
·
Een
beveiliging met rollen (vb. employee, superuser of administrator) die
functionaliteit van de applicatie voor een gebruiker bepaalt.
Voor we aan
het echte OO-ontwerp begonnen hebben we eerst een algemene package-structuur
uitgedacht. Oorspronkelijk dachten we
aan een structuur die de lagen in de applicatie voorstelt nl.:
·
Een
package web met de Struts-klasses.
·
Een
package model met de business-klasses.
·
Een
package db met de database-gerelateerde objecten.
De
co-promotor binnen VRT raadde echter aan dit te wijzigen in een structuur die
meer gebaseerd is op het domein-model (nl. de packages user, category, faq,
message en util). Elke “domein”-package
wordt daarna opgedeeld in sub-packages die de lagen in de applicatie kunnen
voorstellen (nl. web, model, db en exceptions).
Dit bleek meer werkbaar en uitbreidbaar.
Om zo
weinig mogelijk tijd te verliezen hebben we het OO-ontwerp onmiddellijk met de
tools van Together for Eclipse uitgewerkt.
Een state-transit-diagram en een sequence-diagram lieten toe de werking
van de applicatie (vb. Struts) beter te begrijpen. We hebben ons echter vooral geconcentreerd op
de klassediagramman van de business-laag.
Verschillende design patterns zoals proxy, state, composite, DAO, simple
factory,… zorgen voor een flexibel ontwerp.
Het met Together genereren van code vanuit het OO-ontwerp, leverde een
serieuze tijdswinst op bij de eigenlijke implementatie. Ook van de round-trip-mogelijkheden van
Together is dankbaar gebruik gemaakt, bijvoorbeeld voor het documenteren van
het project.
We hebben
het OO-ontwerp veel aandacht gehad voor de opdeling in de 5 lagen: web,
applicatie logica, business logica, data-access en database. “Wat de applicatie doet” hoort bijvoorbeeld
thuis bij de controller in de applicatielaag (in dit geval de
struts-actions). “Hoe iets wordt gedaan”
hoort thuis in de businesslaag (in de methods van de klasses in het model).
Een use case
legt uit hoe de eindgebruikers de software zullen gebruiken. Het bevat de stappen die een gebruiker
uitvoert om iets met de applicatie te bereiken en de reacties van het systeem.
De use-cases
van de eerste iteratie uit het functional
decomposition diagram, kunnen ook in een use-case-diagram worden
voorgesteld.
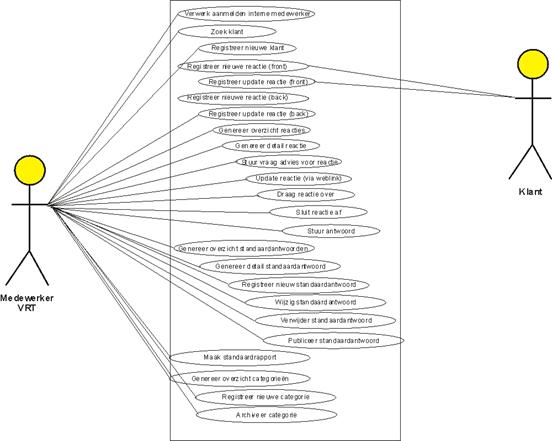
Alle
use-cases voor de eerste iteratie zijn zorgvuldig uitgeschreven. Ze zijn als bijlage terug te vinden op de
bijhorende CD-rom.
Als
use-case template werd het model van Alistair Cockburn (http://alistair.cockburn.us) gebruikt:
USE CASE #
|
De naam en het nummer van de use case.
|
|
Goal in Context
|
Een beschrijving van de doelstelling van de use case.
|
|
Preconditions
|
De zaken die op voorhand beschikbaar moeten zijn om de use case te
kunnen uitvoeren.
|
|
Success End Condition
|
Het resultaat na een succesvolle uitvoering.
|
|
Failed End Condition
|
De toestand als de use case niet goed wordt uitgevoerd.
|
|
Primary,
Secondary Actors
|
De actoren die een rol spelen binnen de use case.
|
|
Trigger
|
De actie binnen het systeem die de use case laat starten.
|
|
DESCRIPTION
|
Step
|
Action
|
|
De actor aan zet
|
1
|
Het normale verloop van de use case van begin tot einde, uitgedrukt in
verschillende stappen.
|
|
Reactie van het systeem
|
2
|
<...>
|
|
|
3
|
|
|
EXTENSIONS
|
Step
|
Branching Action
|
|
|
1a
|
Indien er op een bepaald moment binnen de uitvoering van een taak
verschillende mogelijkheden zijn, worden deze hier besproken. Andere
mogelijkheden worden met een bijkomende letter aangeduid.
|
|
SUB-VARIATIONS
|
|
Branching Action
|
|
|
1
|
Op deze plaats worden mogelijke variaties van een bepaalde stap
aangegeven.
|
|
RELATED INFORMATION
|
De naam van de use case
|
|
Priority:
|
Het belang van de taak binnen het systeem
|
|
Performance
|
De tijd die de taak in beslag mag nemen
|
|
Frequency
|
De frequentie waarmee een taak wordt uitgevoerd
|
|
OPEN ISSUES
|
Zaken die nog niet duidelijk zijn binnen de beschrijving
|
|
Due Date
|
Datum
|
|
...any other
management
information...
|
Aanvullende
informatie
|
|
Superordinates
|
Het niveau in het FDD boven deze use case
|
|
Subordinates
|
Use cases die in het FDD onder deze use case voorkomen
|
Hiervoor
verwijzen we graag naar de uitgebreide Javadoc in HTML-formaat op de bijhorende
cd-rom ( HTML-documentation > index.html ).
Ook de klassediagrammen en UML-diagrammen zijn in het HTML-overzicht
opgenomen.
Een OO-taal
zoals Java heeft een aantal typische kenmerken:
·
Encapsulatie:
data en gedrag worden in objecten weggeborgen.
·
Abstractie:
een structuur van meer algemene en meer specifieke objecten zorgt voor een overzichtelijk
geheel.
·
Overerving: een meer specifiek object kan gebruik maken
van de mogelijkheden van een algemene object.
·
Polymorfie: eenzelfde naam kan verschillende betekenissen
aanduiden bij de verschillende objecten die van elkaar overerven (polymorphism
via overriding) of binnen één object (polymorphism via overloading).
Dit vormt
de basis voor enkele OO ontwerpprincipes die we zo veel mogelijk hebben gebruikt:
·
Wat gelijkaardig is samennemen, wat verschilt afzonderen:
Het
ontwerpen van het domeinmodel verliep bij ons parallel met het maken van de
logische ERD-modellen. Het normaliseren
van die datamodellen en de gebruikte strategieën voor overerving in de
database, gaven zo ook een eerste idee van de evolutie van de compositie en de
overerving in het objectmodel (zie hoofdstukken 3.2.1, 3.2.2 en 3.2.3).
Maar een
objectmodel bevat uiteraard ook gedrag. Een vertrekpunt voor het bepalen waar gedrag
kan thuishoren, is het principe van “informatie expert”. Hierbij is het object dat over de info
beschikt om iets uit te voeren, best ook verantwoordelijk om het te doen. Dit principe gecombineerd met het domeinmodel,
volstond voor de businesslogica die we niet met patronen hebben gemodelleerd.
·
Een ontwerp moet open zijn voor uitbreiding en gesloten voor aanpassing:
Een goed
ontwerp moet voorbereid zijn op verandering.
Wijzigen in de bestaande code hebben echter dikwijls een sneeuwbal-effect
doorheen de rest van de code.
Programma’s kunnen hierdoor onbetrouwbaar worden. De werkende, bestaande code kan dus beter
gesloten blijven voor aanpassingen.
Wijzigingen
kunnen beter geïmplementeerd worden door het toevoegen van nieuwe code en het
gebruik van overerving. Een ontwerp dat
open is voor uitbreiding zal op de juiste plaatsen abstractie inbouwen. Te veel abstractie inbouwen maakt het geheel echter
onoverzichtelijk. Het komt er op aan die
plaatsen te identificeren waar verandering waarschijnlijk is.
Uit de
interviews bij de analyse bleek een duidelijke vraag om ook andere soorten
boodschappen te kunnen versturen via websites (antwoorden op spelletjes,
nieuwstips,…). Dit bracht ons op het
idee een abstracte klasse boodschap (“Message”) in het model op te nemen (zie
onderstaand klasse-diagram). De
gemeenschappelijke kenmerken van een boodschap (reacties of andere soorten
toekomstige boodschappen) verhuisden naar die klasse. We hebben uiteindelijk onze ingebouwde
flexibiliteit ook gebruikt, zoals zal blijken uit het eerste patroon in het
volgende hoofdstuk.
Een
klassieker bij een OO-ontwerp is het samennemen van alle soorten gebruikers in
een abstracte klasse gebruiker (“User”).
Omdat in een tweede iteratie vooral het gedeelte van gebruikers zou uitgewerkt
worden, was het inbouwen van de nodige flexibiliteit ook hier noodzakelijk.
·
Zorg voor een lage koppeling tussen klassen:
Objecten
die elkaar gebruiken maar tegelijk weinig van elkaar afhankelijk zijn, kunnen
gemakkelijk worden herbruikt in andere situaties.
Ook dit
principe hebben we doorheen het project proberen toe te passen. Een rapport gemaakt met Together (hoofdstuk 5.3.2)
toont dat de koppeling tussen de objecten over het algemeen laag is.
Design
patterns zorgen niet alleen voor een flexibel design, maar ook voor een
herkenbare softwarestructuur. In
onderstaande paragrafen worden de gebruikte design patterns van de businesslaag
besproken. Patterns die te maken hebben
met Struts en Hibernate, komen aan bod bij de uitleg over de frameworks
(hoofdstuk 3.4 en hoofdstuk 4.6).
Onderstaand
schema toont niet alleen de implementatie van het Proxy-pattern, het is ook een
illustratie van bovenstaande principes (compositie, abstractie,…)
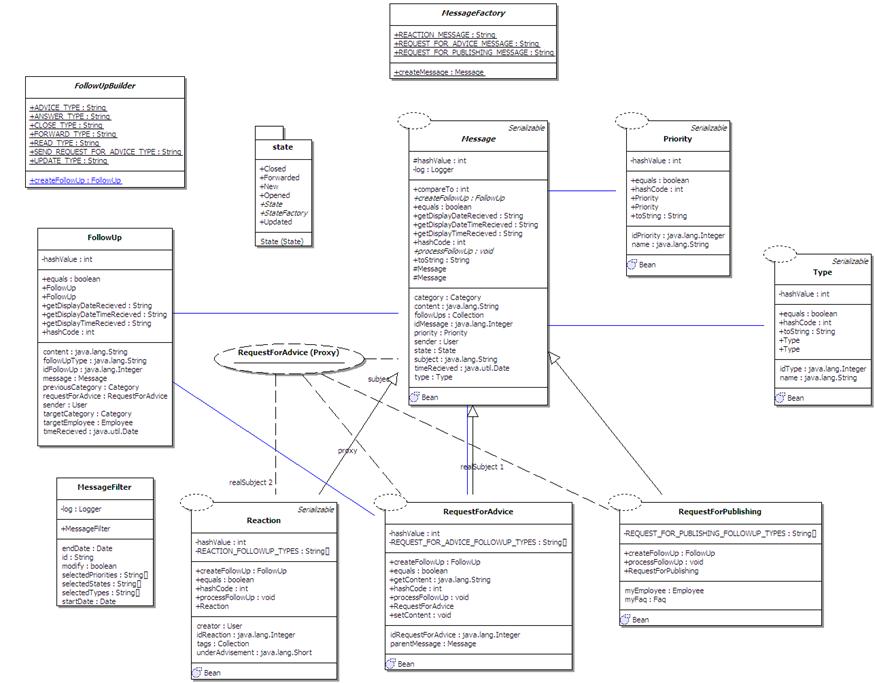
Bij het
uitschrijven van de use-cases kwam een probleem van rechten naar boven. Het probleem werd uitgelegd in hoofdstuk 3.2.3:
“Een vraag voor advies moet onder meer kunnen
gericht worden aan een andere categorie (vb. een vraag over een boodschap in de
categorie “één” aan de categorie “blokken”).
Maar een medewerker aan wie de vraag gericht is, heeft niet noodzakelijk
rechten op de oorspronkelijke boodschap (een medewerker die de categorie
“blokken” beheert heeft niet noodzakelijk rechten op de categorie “één”).”
In het
datamodel was een vraag voor advies eerst als een aparte follow-up
gemodelleerd. Telkens alle follow-ups
van de boodschappen doorzoeken om te bepalen of iemand rechten heeft, is door
het grote aantal boodschappen onmogelijk.
De
flexibiliteit van de abstracte klasse boodschap (zie vorig hoofdstuk) en het
gebruik van het Proxy-pattern boden een oplossing. Eén van de toepassingen van een Proxy is
beveiliging. Een Proxy kan gebaseerd op toegangsrechten, toegang verlenen
tot een ander object. Op een nieuwe
soort boodschap, namelijk een “vraag voor advies”, kan een medewerker wel
eenvoudig rechten krijgen. Via dit
object kan dan de oorspronkelijke boodschap worden opgevraagd.
Eén van de
grootste problemen bij het huidige systeem voor reactieverwerking via email, is
het gebrek aan een status. Reacties
worden naar meerdere personen gestuurd, worden doorgestuurd of “vergeten”. Door de verspreide gegevens is het onmogelijk
een overzicht te behouden. Bij een
gecentraliseerd systeem kan dit uiteraard wel.
Omwille van
het belang van de statussen en de overgangen tussen de statussen hebben we dit
met het State pattern geïmplementeerd.
De logica
of algoritmes die worden uitgevoerd bij het wisselen van status (vb. het
opslaan van de follow-up, het versturen van een email,…) zijn in principe een
implementatie van het Strategy-pattern. Het
gedrag van een boodschap-object wordt at runtime gewijzigd door er
verschillende implementaties van State aan te koppelen. Het grote verschil tussen Strategy en State
is echter dat bij Strategy het gedrag door een externe bron wordt gewijzigd,
terwijl een State-object dit zelf doet.
Onderstaand
sequence diagramma toont het creëren van een nieuwe Reactie. Er wordt twee maal een Simple Factory
gebruikt.
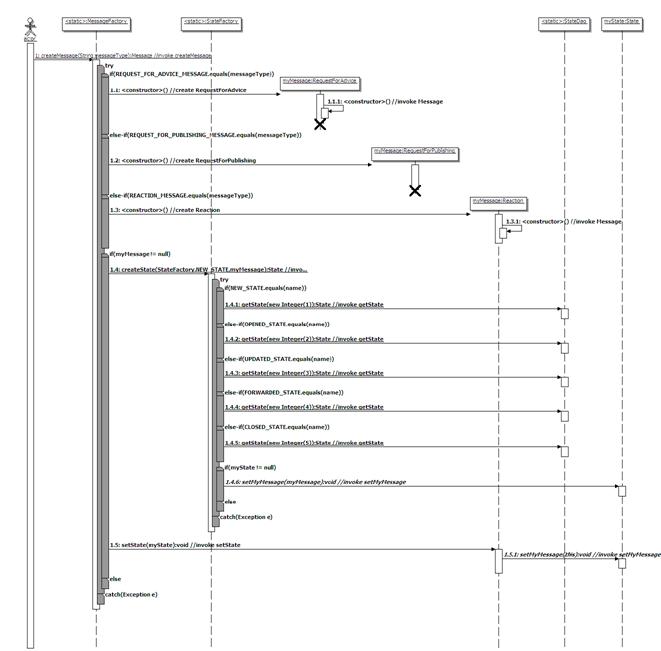
Zoals uit
de klassediagrammen uit de vorige hoofdstukken blijkt, zijn zowel een boodschap
als een status abstracte klassen. Alle
kennis over de bestaande concrete afgeleide klassen en de logica om ze te creëren,
hebben we gegroepeerd in twee “Simple Factories”. Nieuwe soorten boodschappen of statussen
toevoegen, kan nu door op één plaats de code aan te passen. Door de Factories een referentie te laten
retourneren van de abstracte klasse, wordt het principe van inversion of
control toegepast. Klassen in de
applicatie zijn niet meer afhankelijk van de concrete klassen maar van een
abstractie.
Het pattern
voor een hiërarchische structuur is uiteraard Composite. Bovenstaande figuur toont hoe we dit hebben
geïmplementeerd met de Jenkov klassen. Voor
het gebruiken en aanpassen van de faq’s hebben we een composite-structuur
gemaakt met CategoryNodes als composite-objecten en FaqNodes als leaf-objecten. Voor de presetatie in de view worden de root
en enkele kenmerken van de boomstructuur opgeslagen in een FaqTree-object.
FaqNode en
CategoryNode zijn “lichte” versies van Faq en Category. Om de gebruikte resources zo laag mogelijk te
houden, worden voor de nodes enkel die properties uit de persistentielaag
gehaald die nodig zijn voor de boomstructuur in de view. Dit J2EE pattern is het light-weight pattern.
De
Jenkov-klassen en het principe om bij het open of dichtklappen van de boom
telkens de zichtbare nodes op te halen uit de persistentielaag, bleek in de
praktijk goed te werken.
We
gebruiken in onze applicatie per businessobject een Data Access Object (DAO) om
de toegang tot de persistentielaag te groeperen. Hibernate heeft een eigen API en een op
objecten gebaseerde Hibernate Query Language (HQL). Met DAO’s is persistentie-gerelateerd code
gemakkelijk terug te vinden en wordt de applicatie minder afhankelijk van één
bepaalde persistentietechnologie.
We hebben
de methodes in de DAO’s static gemaakt.
Dit spaart ons het creëren van concrete objecten uit. Deze manier van werken heeft echter het
nadeel dat overerving bij DAO’s niet kan gebruikt worden.
Hibernate
maakt gebruik van proxies om de applicatie te optimaliseren. Een proxy regelt de toegang tot het echte
object. In Hibernate wordt deze techniek
gebruikt om niet alle attributen van een object te moeten laden. Binnen een Hibernate sessie worden attributen
dynamische uit de database opgehaald wanneer ze nodig zijn.
Lazy
loading wordt in het hoofdstuk over Hibernate besproken.
Het
tread-local pattern maakt eenzelfde instantie van een object beschikbaar voor
de hele thread. We gebruiken dit pattern om een Hibernate sessie object (en de
bijhorende cache) te kunnen delen tussen verschillende DAO’s.
De
implementatie van het thread local pattern wordt in het hoofdstuk over
Hibernate besproken.
Het Front
Controller pattern is een aangepast MVC-patroon voor webapplicaties. Het wordt besproken in het hoofdstuk over
Struts.
In een
OO-omgeving betekent het decorator patroon het dynamisch (at runtime) toevoegen
van nieuw of aanvullende gedrag aan een methode van een object. Het decorator object “wrapt” het
oorspronkelijke object.
Als men het
decorator patroon toepast op een object gaat men het decorator object rond het
oorspronkelijke object “wrappen”. Typisch wordt dit bereikt door het
oorspronkelijke object als parameter mee te geven aan de constructor van de
decorator. Het decorator object zal dan de nieuwe functionaliteit
implementeren. De interface van het originele object blijft evenwel bewaard.
Het
decorator patroon werd binnen de applicatie toegepast door SiteMesh. Sitemesh
onderschept elke request naar een statische of dynamisch gegenereerde
HTML-pagina op de webserver. Vervolgens gaat Sitemesh, nadat de gevraagde pagina
samengesteld is, na of voor de pagina een decorator gedefinieerd is. Indien dit
het geval is, zal deze door SiteMesh rond de gegenereerde inhoud worden
“gewrapt”. De decorator zal met andere woorden de oorspronkelijke inhoud van de
pagina aanvullen met extra inhoud. Concreet gaat het bijvoorbeeld om de titel
van de HTML-pagina die wordt aangepast, een header die wordt toegevoegd aan de
HTML-pagia etc. De gebruiker zal uiteindelijk de gedecoreerde pagina te zien
krijgen.
Het
onderstaande flow-diagram illustreert de werking van Sitemesh.
Het eerste wat opvalt bij het
bezoeken van de site struts.apache.org
is dat er twee soorten Struts bestaan.
Het zogenaamde Struts Action framework wordt soms ook wel Struts Classic
genoemd. Het Struts Shale framework is
later ontwikkeld en baseert zich op Java Server Faces (JSF). Dit is een Java API voor het maken van
grafische interfaces voor web applicaties.
Het Struts Action framework is echter de de-facto standaard.
Voor ons
eindwerk hebben we steeds technologieën verkozen die zichzelf hebben
bewezen. Bovendien zijn voor het Struts
Action Framework veel meer informatie en tools beschikbaar. Vooral de “officiële” gebruikersgids op de
site van struts (http://struts.apache.org/struts-action/userGuide)
en de tools van MyEclipse waren nuttig. Daarom
leek het Struts Action Framework de beste keuze.
Struts
uitleggen in een notendop, is niet eenvoudig.
De “officiële” gebruikersgids begint met een lange opsomming van de
elementen die je grondig moet begrijpen voor je met Struts kan beginnen. Veel elementen zijn beschreven in het J2EE
gebruikershandleiding (http://java.sun.com/j2ee/1.4/docs/tutorial/doc/index.html).
Onderstaand
lijstje toont enkele kernbegrippen.
Sommigen worden in het laatste hoofdstuk verder uitgelegd:
·
Http request/response cirkel: de gebruiker stuurt een http request naar de
server waarop deze moet antwoorden.
·
Multithreading: verschillende
sequentiële taken binnen een programma die tegelijk worden uitgevoerd.
·
JavaBeans: pattern dat onder meer toelaat de publieke
fields en methods van een object te bepalen via reflectie en introspectie.
·
Properties files en ResourceBundles: veelgebruikte methode voor het configureren
van een Java-applicatie.
·
Http-servlets: belangrijk J2EE-element dat een
http-request-response-structuur vertaalt naar een OO-omgeving.
·
Java Server Page (JSP): de html-represenatie van een servlet. Wordt deels geprecompiled, deels at-runtime
omgezet naar een servlet.
·
Taglibs: tags die toelaten
dynamische functionaliteit toe te voegen aan JSP’s.
·
Extensible Markup Language (XML): gestructureerde
voorstelling van gegevens in de vorm van tekst.
De
bespreking van onze implementatie van het Struts Action Framework, is opgedeeld
in 3 delen:
·
De algemene werking van Struts met onder meer het
Front Controller pattern.
·
Een overzicht van onze Struts-implemenatie.
·
Enkele functionaliteiten van het framework die we
hebben gebruikt.
Onderstaande
figuur geeft de klassieke Model-View-Controller-structuur weer.
Het “model”
vertegenwoordigt de business data en logica, de “view” presenteert de inhoud
van het model en de “controller” bepaalt het gedrag van de applicatie. De controller verwerkt de input van de
gebruiker, past eventueel het model aan en selecteert de juiste view voor de
gebruiker. De view wordt samengesteld
door het ondervragen van het model.
Eventuele updates van het model worden via het observer-pattern aan de
view gemeld. Bij een webapplicatie is
een directe link tussen het model en de view echter moeilijk. Het observer-pattern is immers niet bruikbaar.
Bij struts
wordt een aangepast MVC-model gebruikt, namelijk het Front Controller
pattern. Hierbij bepaalt een
gecentraliseerde controller het verloop van het programma. De controller delegeert een http-request naar
een Action. Die Action vertegenwoordigt
een deel van de applicatielogica en werkt samen met het model. De controle wordt daarna via de centrale
controller teruggegeven aan een bepaalde view.
De driehoek van bovenstaande figuur wordt dus meer een hoefijzer.
Een
gecentraliseerde controller biedt bovendien enkele interessante voordelen voor
webapplicaties:
·
Overzicht
houden op de navigatie of de program-flow is eenvoudiger.
·
De
integratie van systeem services (zoals beveiliging) kan op één plaats.
Onderstaand
sequence-diagram toont met een aantal de kernelementen de werking van Struts:
De
ActionServlet is het hart van struts-framework.
Deze centrale http-servlet ontvangt de requests van de browser. Sinds struts 1.1 wordt het grootste deel van
de verwerking van de request verder gedelegeerd naar de RequestProcessor. De struts-controller (ActionServlet en
RequestProcessor) wordt geconfigureerd met één centrale XML-file, de
struts-config.xml. Deze file zal onder
meer de request-url linken (mappen) met een aantal resources uit het
strutsframework (zie ook volgende hoofdstuk).
(Merk op
dat de struts-config.xml-file bij het opstarten van de applicatie geparsed
wordt naar verschillende configuratie-objecten.
Om een bondige overzicht van Struts begrijpbaar te houden, wordt in
onderstaande uitleg niet verwezen naar de configuratie-objecten.)
De
belangrijkste stappen van RequestProcessor zijn:
1. Het eventueel creëren van een ActionForm:
Een
ActionForm kan beschouwd worden als de OO-representatie van een
html-formulier. Het wordt onder meer
gebruikt om gegevens te transporteren van de ‘view’ naar de ‘controller’. In de struts-config.xml wordt nagegaan welke
ActionForm gekoppeld is aan de gevraagde url.
Als in de request- of session-buffer een instantie van deze ActionForm
bestaat, wordt ze herbruikt. Anders
wordt een nieuwe instantie aangemaakt.
2. De methode processPopulate ‘vult’
het ActionForm met de input van het http-request:
Voor elk
attribuut uit het http-request met eenzelfde naam in ActionForm, wordt de
overeenkomstige set-functie in het ActionForm opgeroepen.
3. De methode validate controleert de
input:
De
input-gegevens kunnen gecontroleerd worden met validatieregels uit een
validation.xml-file. Eventuele
foutboodschappen worden in een ActionErrors-object opgeslagen. Wanneer validate een
ActionErrors-object met foutboodschappen teruggeeft, bepaalt de
struts-config.xml de view (jsp) voor het antwoord.
Wanneer
bijvoorbeeld een html-formulier foutieve input bevat, kan voor het antwoord
terug verwezen worden naar het oorspronkelijke html-formulier (via een
tussenstap met jsp’s). De ActionErrors
worden dan gebruikt om de foutboodschappen te tonen. Via het ActionForm dat de inputgegevens
bevat, kan het html-formulier automatisch opnieuw ingevuld worden. Zo wordt het ActionForm ook gebruikt om
gegevens te transporteren van de ‘controller’ naar de ‘view’.
4. De controle wordt doorgegeven aan een
Action:
Zoals in de
vorige paragraaf beschreven, implementeren verschillende Action-klasses telkens
een deel van de applicatielogica. Via de
struts-config.xml en de request-url bepaalt de RequestProcessor aan welke
Action de controle wordt doorgegeven.
De Action
maakt gebruik van de input uit het ActionForm en werkt samen met de data en de
methodes uit het model (de business-logica).
Om het
antwoord op het request voor te bereiden, kan de Action gebruik maken van de
data in het ActionForm en helper-klassen.
Deze laatste zijn speciale klassen die enkel worden gebruikt bij het
samenstellen van de view. In onze
applicatie is de representatie van de mappen-structuur, een mooi voorbeeld van
een dergelijke Helper-klasse. We maken
voor de weergave van de boomstructuur gebruik van het Jenkov
open-source-project. In de Actions wordt
een composite-structuur gemaakt met de zichtbare TreeNodes (vb.
Categorieën). De boom-structuur wordt
vervolgens bewaard in een Tree helper-klasse.
De view (jsp-pagina) zal tenslotte het Tree object gebruiken om de
mappenstructuur zichtbaar te maken.
Afhankelijk
van de applicatielogica in de Action zijn soms verschillende antwoorden op een
request mogelijk. In de Actions kan via
logische namen (vb. “overviewMessages” of “detailsMessage”) het juiste antwoord
opgezocht worden in de struts-config.xml.
De mapping in deze configuratiefile bepaalt aan welke jsp-pagina (view)
de controle wordt overgedragen.
In een applicatie
wordt de centrale struts-config.xml file snel groot en complex. Er bestaan tools zoals XDoclet, om de
configuratie tussen de code van de verschillende Actions te verwerken. Voor ons project hebben we echter gekozen de
xml-file manueel aan te passen. De tool
van MyEclipse is handig om de applicatieflow visueel voor te stellen en zo het
overzicht te bewaren.
Onderstaande
schemas geven een overzicht van de verschillende Struts-strategieën die we bij
onze implementatie gebruikten. De
gebruikte symbolen kunnen het gemakkelijkst met een voorbeeldje worden
uitgelegd:
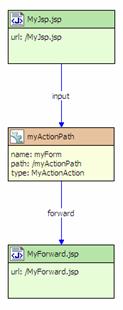
- Jsp-pagina:
stelt de view voor (vb. html-pagina met een formulier)
- Het input-attribuut
in de struts-config.xml: bepaalt per Action welke jsp wordt opgeroepen
wanneer de validatie errors oplevert (hier de MyJsp.jsp file met bv. het
oorspronkelijk formulier)
- Action
(type-attribuut) die via een url (path-attribuut) wordt
opgeroepen. Aan dit path is ook een verwijzing
naar een instantie van een ActionForm (name-attribuut) gekoppeld.
- De forward-tag
in de struts-config.xml: definieert een logische naam (hier ‘forward’) om
vanuit een Action de controle over te dragen aan een jsp-pagina.
In het
front-office kan een kijker in verschillende stappen een reactie invoeren via
het web.

Het begint
met een http-request naar het path /reactionStep01. Wanneer de gebruiker voor het eerst de URL opvraagt,
wordt een instantie van een ReactionStepsForm aangemaakt. Het ReactionStepsForm heeft een session-scope
en zal dus gedurende alle stappen worden bewaard, herbruikt en aangevuld. Het werken met één groot ActionForm voor verschillende
Actions wordt dikwijls aangeraden voor een betere performantie (geen onnodige
initialisaties van objecten) en onderhoudbaarheid (overzicht).
Merk op dat
het name-attribuut in elke Action verschilt (reactionStep01Form,
reactionStep02Form,…). Ze verwijzen
echter allen naar hetzelfde ReactionStepsForm (op een andere plaats in de
struts-config.xml). Met de verschillende
name-attributen kunnen voor elke url andere validatieregels worden gebruikt.
De
registerReactionStep01Action creëert een JCaptcha-challenge ( http://jcaptcha.sourceforge.net/ ).
Dit is een willekeurige, gegenereerde jpeg-code die de gebruiker moet
kopiëren (zie hoofdstuk 5.1.3.4). Ze
beschermt de applicatie tegen ‘geautomatiseerde’ reacties via scripts. Wanneer de code is gecreëerd, wordt in de
Action de mapping voor de naam ‘success’ opgezocht. ReactionStep01.jsp bouwt het eerste scherm met
de JCaptcha-code op.
De
gebruiker vult vervolgens zijn email-adres, naam, voornaam en de JCaptcha-code
in en submit het formulier naar het path /reactionStep02. De validatieregels voor reactionStep02Form
controleren op lege velden en een geldig email-adres. Bij validatie-errors zal reactionStep01.jsp
terug het beginscherm genereren (input-attribuut), de ingevulde velden opnieuw
invullen en de foutboodschap(pen) tonen.
Is de
validatie van de input in orde, dan handelt de ReactionStep02Action het request
verder af. De ingevoerde JCaptcha-code wordt
vergeleken met het verwachte resultaat. Bij
een foutieve code wordt de mapping voor ‘failure’ opgezocht. Bij een correcte code wordt een nieuwe
instantie van een Reaction met het email-adres en de naam, in de sessie
opgeslagen. Vervolgens wordt de mapping
voor de naam ‘success’ opgezocht.
Dit kleine
voorbeeld toont een veelgebruikte strategie bij struts. Eenvoudige validatie (zoals lege velden of
een correct email-adres) wordt met het framework afgehandeld, complexe
validatie (zoals de validatie van de JCaptcha-code) door de Action.
De verdere
stappen volgen gelijkaardige principes.
Telkens wordt gecontroleerd of een instantie van een Reaction in de
sessie aanwezig is. Indien niet, dan
wordt de mapping met de naam ‘failure’ opgezocht. In stap 05 wordt de reactie opgeslagen. Deze stap heeft geen nieuwe input. Eenmaal de reactie is opgeslagen worden de
Reaction in de sessie gewist.
De
volledige applicatie-flow van de back-office beschrijven is weinig zinvol. Het is nuttiger enkele principes op een rij
te zetten.
In onze
applicatie is veel aandacht besteed aan error-handling en het werken met chained
exceptions. Dit laat toe aan de
gebruiker een begrijpbare boodschap te tonen en tegelijk alle details van de
fout te bewaren met log4J (zie hoofdstuk 5.1.2.5). Onderstaand schema toont een deel van de
error-handling in onze applicatie. In de
struts-config.xml wordt een global forward ‘error’ gedefinieerd. Vanuit elke Action in de applicatie kan de
mapping voor de ‘error’ worden opgeroepen. In de errorAction.jsp zal een fout uit een
Action eerst op een hoog niveau uitgelegd worden (voor de gebruiker), daarna steeds
gedetailleerder (voor diegene die de fout moet oplossen).
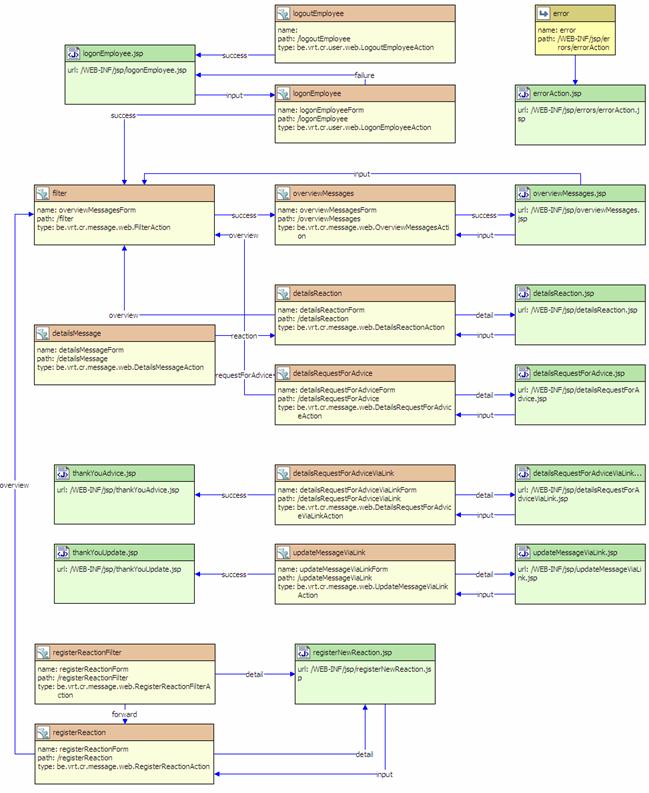
De schermen
in onze applicatie bevatten veel informatie en functionaliteit. Zo kan de gebruiker vanuit één scherm snel de
gewenste actie uitvoeren. Een
http-formulier kan echter slechts naar één url en dus naar één Action gestuurd
worden. Alle functionaliteit in die ene
Action proberen duwen, is onoverzichtelijk en tegen de principes van een goed
OO-ontwerp. In struts kan een Action via
een mapping ook een andere Action oproepen (ipv. een jsp). Bij het bouwen van onze applicatie hebben we
dit principe vaak toegepast. Hoe meer we
met struts bezig waren, hoe kleiner de Actions werden en hoe duidelijker hun functionaliteit afgelijnd
werd. Kleinere Actions laten bovendien
toe per url andere validatie-regels te definiëren. Enkel voorbeelden uit bovenstaand diagramma:
- De
weergave van de details van een boodschap is afhankelijk van het soort
boodschap (vb. RequestForAdvice, Reaction,…).
Voor een flexibele design wordt een request die details van een
boodschap opvraagt, eerst naar de DetailsMessageAction gestuurd. Dit is een soort dispatcher. In de DetailsMessageAction wordt de concrete
klasse van de boodschap (RequestForAdvice, Reaction,…) bepaald. Aan de hand hiervan wordt het request
doorgestuurd naar een Action voor die concrete klasse (RequestForAdviceAction,
ReactionAction,…). Die bevat alle functioniteit
voor een bepaald soort boodschap. Het
eventueel toevoegen van andere soorten boodschappen wordt door het gebruik van
de dispatcher eenvoudig.
- Voor het
overzicht van de reacties hebben we de functionaliteit voor het filteren van
opgevraagde reacties in een aparte FilterAction ondergebracht. De FilterAction kan een MessageFilter-object
initialiseren, resetten of klaarmaken om te updaten. Het ophalen van de reacties zelf gebeurd in
de OverviewMessagesAction.
- Een mooie
opdeling wordt ook gebruikt bij het registeren van een nieuwe Reaction. Dit proces bevat eigenlijk twee delen nl. het
invullen en/of opzoeken van de gegevens van de klanten en het
invullen van de gegevens van de reactie.
De RegisterReactionFilterAction neemt de functionaliteit van de klanten
voor zijn rekening., terwijl de RegisterReactionAction de functionaliteit voor
een Reactie bepaalt.
Verder
bouwend op het succes van bovenstaande principe, zijn we bij het implementeren
van de functionaliteit van de faq’s nog een stap verder gegaan. Onderstaand schema toont de verschillende
acties die op een faq kunnen uitgevoerd worden.
Elke actie heeft zijn eigen Action-klasse. De FaqDispatchAction bevat de
gemeenschappelijke functionaliteit voor een faq en zal het request forwarden
naar een specifieke Action-klasse.
Struts
ondersteunt dit principe met de abstracte klasse DispatchAction. Onze implementatie heeft echter een nog
grotere flexibiliteit. Met onderstaande
twee regels code uit de FaqDispatchAction wordt een request automatisch
doorgestuurd aan de hand van een parameter in de view.
if(myForm.getSubmitType()!=null){
return mapping.findForward(
myForm.getSubmitType() );
}
Een
eventuele nieuwe actie voor faq kan nu in de applicatie ‘ingeplugd’ worden,
zonder de DispatchAction te moeten aanpassen!
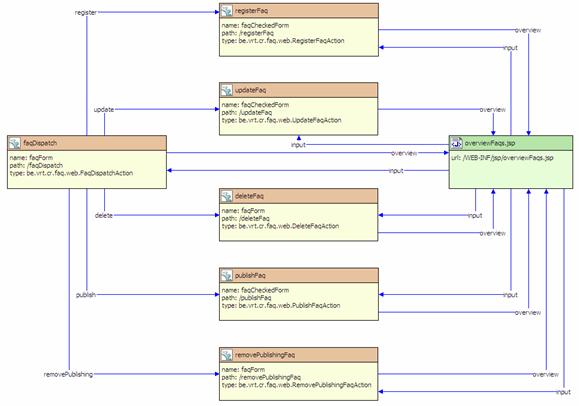
Het struts-framework biedt naast de
standaard-features, door zijn open structuur veel mogelijkheden tot uitbreiding. Het toevoegen van functionaliteit kan meestal
eenvoudig door de struts-config.xml aan te passen. Uiteraard kunnen ook de principes van
overerving worden gebruikt.
Onderstaande tekst toont een stukje
uit onze struts-config.xml.
<!-- Custom requestprocessor to
handle the security for the actions -->
<controller>
<set-property
property="processorClass"
value="be.vrt.cr.util.web.CrRequestProcessor"/>
</controller>
<!-- Messages for struts -->
<message-resources parameter="be.vrt.cr.util.web.ApplicationResources" />
<!-- Application plugin -->
<plug-in className="be.vrt.cr.util.web.Initialization">
</plug-in>
<!-- Validator plugin -->
<plug-in className="org.apache.struts.validator.ValidatorPlugIn">
<set-property property="pathnames"
value="/WEB-INF/validator-rules.xml,/WEB-INF/validation.xml"/>
</plug-in>
<!-- CaptchaPlugin -->
<plug-in className="com.octo.captcha.module.struts.CaptchaServicePlugin">
<set-property property="serviceClass" value="be.vrt.cr.util.web.captcha.service.DefaultManagableCaptchaService"/>
</plug-in>
Met het controller element kan onder
meer de gebruikte RequestProcessor worden bepaald. In onze applicatie hebben we een eigen klasse
CrRequestProcessor gemaakt die overerft van de originele RequestProcessor. Dit liet ons toe een eigen systeem voor de
beveiliging van de Actions te implementeren (zie hoofdstuk 4.6.4.3).
Het message-resources element
bepaalt de resource-files voor het ondersteunen van meerdere talen. In onze applicatie gebruiken we deze optie om
het Engels (de applicatie-logica) te scheiden van het Nederlands (de
view). Een foutboodschap in een
validatie-methode zal bijvoorbeeld een Engelstalige verwijzing (key) bevatten
uit de resource-file. In de html-pagina
wordt de corresponderende Nederlandstalige vertaling (value) uit de
resource-file getoond.
Onze struts-config.xml toont ook
drie plugin’s. Een plugin-klasse
implementeert de interface org.apache.struts.action.Plugin en bevat de methodes
init( ) en destroy( ). Ze worden opgeroepen
bij het starten en afsluiten van de applicatie.
De klasse Initialization is een zelfgemaakte
plugin voor het configureren van de applicatie.
Met de ValidatorPlugin kan de input eenvoudig client- en server-side
worden gevalideerd (zie hoofdstuk 4.6.4.2).
Tot slot wordt de service die JCaptcha levert, geïnitialiseerd met de
CapchaServicePlugin (zie hoofdstuk 5.1.3.4)
Validatie
van de input kwam in het hoofdstuk over de OO-analyse al enkele keren aan
bod. De werking van de validate-methode
in een ActionForm werd uitgelegd bij het sequence-diagram over struts (zie hoofdstuk
4.6.2). Het controleren van de input
door in elke ActionForm de methode validate( ) te implementeren, zou voor veel
gelijkaardige code zorgen (vb. controle op lege velden). De validatie-logica kan dus beter worden
afgezonderd. Het Jakarta Validator
Framework biedt een kant en klare oplossing en is perfect in struts
geïntegreerd.
In de
struts-config.xml worden bij de validator-plugin twee xml-files vermeld (zie
hoofdstuk 4.6.4.1). Ze worden gebruikt
voor het configureren van Validator.
1. Validation.xml:
Deze file koppelt
de validatieregels aan de properties van “een verwijzing naar” een
ActionForm. De woorden “een verwijzing
naar” zijn belangrijk. Validatieregels
worden niet rechtstreeks gekoppeld aan een ActionForm. Onderstaand een voorbeeldje uit de
validation.xml.
<form-validation>
<formset>
<!-- … -->
<form name="reactionStep02Form">
<field property="name" depends="required">
<arg0 key="label.name"/>
</field>
<field property="firstname" depends="required">
<arg0 key="label.firstname"/>
</field>
<field property="email" depends="required,email">
<arg0 key="label.email"/>
</field>
<field property="jcaptcha_response" depends="required">
<arg0 key="label.code"/>
</field>
</form>
<!--
… -->
</formset>
</form-validation>
Bij het
overzicht van de Actions en de JSP’s in het Front-Office (hoofdstuk 4.6.3.1)
werd even aangeraakt dat het ReactionStepsForm wordt herbruikt bij de
verschillende stappen in het registratieproces van een reactie. Maar elke stap gebruikt andere
validatieregels. Een request naar
bijvoorbeeld de url /reactionStep02 zal gevalideerd worden met “reactionStep02Form”. “reactionStep02Form” verwijst naar ReactionStepsForm,
waar de properties effectief zijn opgeslagen.
Het element
“arg0” is een mooi voorbeeldje van het gebruik van de resource-file om het
Engels (in de implementatie) en het Nederlands (in de view) van elkaar te
scheiden (zie hoofdstuk 4.6.4.1). Het
element “arg0” bepaalt de Engelstalige key die gebruikt wordt bij een eventuele
foutboodschap. In de jsp wordt de
Nederlandstalige value voor deze key opgezocht.
2. Validation-rules.xml:
Deze file
beschrijft de eigenlijk validatieregels die in validation.xml gebruikt worden. De
meest courante validatieregels zijn door het validator-framework geïmplementeerd
(required, requiredif, maxlenght, mask, byte, short, integer, long, double,
date, range, intRange, floatRange, creditCard en email). In validation-rules.xml kunnen eigen regels worden toegevoegd.
Bij struts
1.2 bevat de validation-rules.xml voor elke validatieregel ook
javascript-code. Die code kan met een
html-response worden meegestuurd. Zo
wordt client- en server-side validatie gelijktijdig gebruiken eenvoudig.
We hebben
in onze applicatie zo veel mogelijk gebruik gemaakt van het validator-framework
en client-side validatie. Dit laatste is
vooral belangrijk voor de grote werklast van de servers (250000 reacties per
jaar). Door de input met javascript te
controleren in de browseromgeving van de klant, worden onnodige requests naar
de server vermeden.
De
beveiliging van de webapplicatie gebeurt op verschillende niveau’s. Voor de meeste functionaliteit in de
back-office is een login met een email-adres en een paswoord noodzakelijk. Na verificatie in de database wordt de
gebruiker in de sessie bewaard.
Dit
hoofdstuk behandelt de beveiliging op het niveau van de functionaliteit. Wie kan wat in de applicatie? Uit het context-diagramma en de logische
ontwerp van de database bleek dat de gebruikers kunnen worden opgedeeld in
groepen (employee, superuser en administrator).
Struts ondersteunt
perfect het idee van groepen met het begrip “role”. In de struts-config.xml kan worden bepaald
door welke rollen een Action kan worden uitgevoerd. Het kwam er dus op aan de struts-role te
vergelijken met een role (groep) van onze gebruiker.
Struts is
een heel uitbreidbaar framework. In de
struts-config.xml hebben we een nieuwe CrRequestProcessor gedefinieerd die
overerft van de default RequestProcessor.
Hierin hebben de methode processRoles( ) een nieuwe implementatie
gegeven die de twee rollen vergelijkt.
protected boolean processRoles(
HttpServletRequest request,
HttpServletResponse response,
ActionMapping mapping
) throws IOException, ServletException
{
Employee myEmployee = null;
String roles[] = mapping.getRoleNames();
HttpSession mySession =
request.getSession(false);
if(roles == null || roles.length < 1){
log.debug("no role requered for
this action.");
return true;
}
if(mySession!=null &&
mySession.getAttribute("user") != null)
{
for(int i = 0; i < roles.length; i++)
try{
myEmployee = (Employee)
mySession.getAttribute("user");
if(myEmployee.getRole().getName().equals(roles[i]))
{
log.debug(" user
'" + myEmployee.getFirstName() + " " +
myEmployee.getName() + "' has role
'" + roles[i] +
"', granting access");
return true;
}
}
catch(ClassCastException
cce){}
}
log.error(" user does not have the
required role, denying access");
response.sendError(
400,
getInternal().getMessage(
"notAuthorized",
mapping.getPath()
)
);
return
false;
}
In dit hoofdstuk
wordt de concrete ontwikkeling van de applicatie besproken. In de eerste paragraaf
worden de gebruikte technologieën algemeen besproken. Het tweede paragraaf
presenteert een aantal screenshots die aantonen hoe de functionaliteit van de
applicatie voor de gebruiker beschikbaar gemaakt wordt. In een derde paragraaf,
worden tot slot enkele resultaten van uitgevoerde tests getoond.
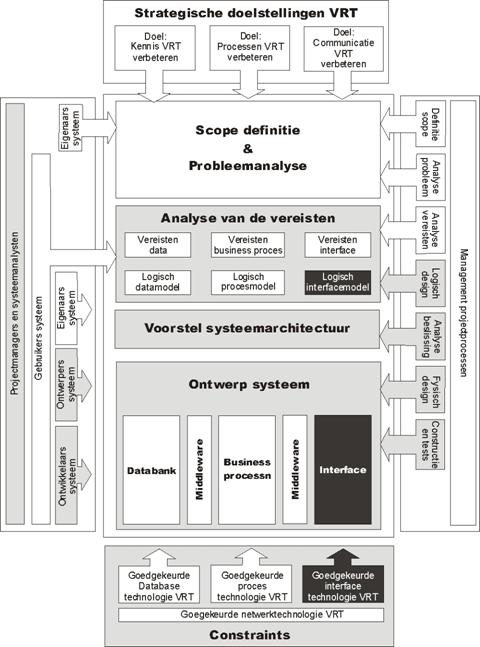
In deze paragraaf
worden de technologieën besproken die voor de ontwikkeling van de applicatie
werden gebruikt. De technologieën Hibernate en Struts werden reeds eerder
besproken omwille van hun nauwe samenhang met het ontwerp van de databank en
van het klassemodel. Daarom zullen deze hier enkel voor de volledigheid worden
aangehaald. Voor een uitgebreide bespreking kan men terecht in de vorige
hoofdstukken.
In eerste
instantie zal een algemeen schema gepresenteerd worden waarin alle gebruikte
technologieën een plaats hebben gekregen en waarin de samenhang tussen de
technologieën wordt verduidelijkt. Vervolgens zullen de technologieën elk
afzonderlijk worden beschreven. Om het overzichtelijk te houden wordt eerst de ontwikkelingstool
besproken om dan in te zoomen op elke technologie afzonderlijk, binnen de laag van de toepassingen waarbinnen
ze te situeren valt. Elke technologie wordt eerst kort algemeen beschreven,
waarna het concrete gebruik van de technologie binnen de applicatie wordt
geschetst. Indien relevant wordt een klein code-voorbeeld of een screen-shot
weergegeven om bepaalde zaken te verduidelijken. Voor een dieper inzicht in de
geproduceerde code kan men terecht in de bestanden van de applicatie zelf.
De
onderstaande afbeelding geeft een goed beeld van de opbouw van de applicatie:
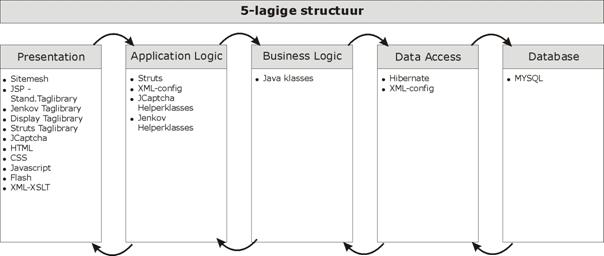
Er werd voor geopteerd om de
applicatie in vijf verschillende lagen op te bouwen.
De presentatielaag bevat alle technologie die gebruikt wordt om de
interface tussen gebruiker en applicatie te realiseren. In ons geval ging het
om een applicatie die in een browseromgeving moet werken. De technologieën die
hier onder vallen zijn dan ook veelal webtechnologieën, zoals HTML, Javascript,
JSP etc.
Onder de applicatielaag wordt hier de controlelaag bedoelt, die presentatie
en het businessmodel van elkaar scheiden en die de interactie tussen de beide
lagen op een efficiënte, beheersbare en schaalbare manier laat verlopen. Om
deze taak uit te voeren werd een beroep gedaan op het Struts Framework.
De businesslaag bevat het businessmodel van de applicatie. Deze laag
bevat de Java-klasses die gebruikt worden om de verschillende business-taken te
kunnen realiseren die de applicatie moet uitvoeren.
De data-acces laag verzorgt een efficiënte communicatie tussen de
businesslaag en de database. Deze laag zorgt voor de mapping tussen de objecten
en de relationele datastructuur. Binnen de applicatie werd er voor deze taak
een beroep gedaan op het Hibernate framework.
De database-laag tenslotte bevat de technologie die er voor zorgt dat
alle gegevens , opgeslagen worden in een relationeel databanksysteem.
Sommige technologieën komen in
meerdere lagen voor.
In de
onderstaande paragrafen worden de voornaamste ontwikkelingstools besproken die
gebruikt werden tijdens de realisatie van dit eindwerk. Ook wordt hier het JEE
platform besproken omdat dit de brede omgeving is waarbinnen de applicatie tot
stand kwam.
Eclipse is
een gratis, open en universele tool voor de ontwikkeling van software. Met open
wordt bedoeld dat Eclipse een open-source project is. De universaliteit zit in
de innovatieve plug-in georiënteerde architectuur van Eclipse. Deze
architectuur maakt het voor ontwikkelaars mogelijk om gemakkelijk nieuwe
functionaliteit aan Eclipse toe te voegen. Deze functionaliteit kan zeer
verschillende zijn. Het kan bijvoorbeeld gaan om het oplichten van bepaalde
syntax tot XML-tools, UML-tools enz. Waar Eclipse oorspronkelijk voornamelijk
een tool was voor de ontwikkeling van JAVA-programma’s, wordt de Eclipse-IDE
(Integrated Development Environment) omwille van zijn kwaliteit en zijn
open-source natuur, momenteel ook gebruikt voor de ontwikkeling van programma’s
met andere programmeertalen zoals C en C++ of met scriptingtalen zoals PHP.
Eclipse
laat ook toe om plugins te integreren die door commerciële bedrijven worden
ontwikkeld. Een voorbeeld van een dergelijk plugin is MyEclipse. MyEclipse
biedt de nodige extra functionaliteit aan om met Eclipse J2EE toepassingen te
ontwikkelen. De mogelijkheden van MyEclipse zijn zeer ruim. De plugin bevat
tools die goed van pas komen bij het realiseren van de verschillende onderdelen
van een J2EE-applicatie. MyEclipse is een mooi voorbeeld van hoe open-source en
betalende software elkaar kunnen aanvullen.
Meer info: http://www.eclipse.org en http://www.myeclipseide.com
JAVA EE, tot voor kort J2EE genoemd, is een
ontwikkelingsomgeving, ontwikkeld door SUN om robuuste, schaalbare en veilige
server-side applicaties te ontwikkelen met JAVA. JEE applicaties zijn veelal
opgebouwd uit modulair opgebouwde software en draaien doorgaans op een
applicatieserver zoals JBOSS, Glassfish, Geronimo etc. JAVA EE bevat
verschillende API specificaties, zoals JDBC, applets, RPC, en CORBA. Het bevat
ook specifieke onderdelen zoals JAVA Beans, servlets, Java Server Pages(JSP’s)
en webservices.
Meer info: http://java.sun.com/javaee
De JBOSS
applicatie server is een open source applicatie server die volledig in JAVA
ontwikkeld werd. JBOSS implementeert alle services die binnen de Java
Enterprise Edition gedefinieerd worden en vormt dus een solide basis voor de
ontwikkeling van professionele toepassingen. JBOSS is een uitstekend platform
voor het ontwikkelen van webapplicaties, ontwikkeld in JAVA waarbij gebruik
gemaakt wordt van servlets en JSP’s.
De JBOSS
applicatie server integreert o.m. Hibernate en Apache Tomcat. Dit maakte het tot
een geschikt platform voor het ontwikkelen van de applicatie die tijdens dit
project werd gerealiseerd.
Meer info: http://www.jboss.com
CVS staat
voor Concurrent Versioning System. Een dergelijk systeem houdt de verschillende
versies bij van de alle files die bij de ontwikkeling van een project, veelal
een softwareproject worden gecreëerd.
De
CVS-software wordt op een server geïnstalleerd. De verschillende medewerkers
aan het project kunnen nieuwe of gewijzigde bestanden naar de server sturen en
nagaan welke wijzigingen of toevoegingen er door andere medewerkers gebeurden.
Dit maakt het voor ontwikkelaars makkelijker om samen aan één project te
werken, omdat men op die manier een zicht krijgt op de stand van zaken bij de
collega’s. CVS is gratis te downloaden en kan vanuit Eclipse gebuikt worden.
CVS werd
doorheen het hele project goed gebruikt om de verschillende types bestanden te
delen en de versies te beheren. In de praktijk bleek het nut van CVS zeer
duidelijk, zeker omdat men ook de mogelijkheid heeft om terug te keren naar
oudere versies. Er kon van CVS gebruik gemaakt worden dankzij de IT-afdeling
van VRT, omdat zij de technische infrastructuur ter beschikking konden stellen.
Het verdient aanbeveling om CVS ook binnen GroepT ter beschikking te stellen
voor eindwerk-projecten.
Meer info: http://www.nongnu.org/cvs
Log4J is een JAVA-gebaseerde logging-tool. Het is één van de vele
projecten van de Apache Software Foundation. Het wordt voornamelijk gebruikt
als een tool om het programma te testen en te debuggen. Bij deze techniek kan
de ontwikkelaar log-statements in zijn code verwerken. Deze geven de
programmeur gedetailleerde context informatie als er een fout in de applicatie
opduikt, waardoor fouten makkelijker en sneller kunnen worden opgespoord. De
werking van deze tool kan bepaald worden door middel van een afzonderlijk
configuratiebestand, waardoor er niets in de code zelf moet worden aangepast.
Log4J is zo ontworpen dat er niet al te veel aan performantie hoeft te worden
ingeboet.
Meer info: http://logging.apache.org/log4j/docs/index.html
Together is
een UML-tool die ontwikkeld wordt door Borland en die ingezet wordt voor het
modelleren van software. Het pakket laat toe om een applicatie te modelleren en
op basis hiervan code te genereren. Deze kan dienen als basis voor de verdere
ontwikkeling van de applicatie.
Together is
beschikbaar in verschillende smaken. Er is een Architect, een Designer en een
Developer versie op de markt. Tijdens dit project werd gebruikt gemaakt van de
drie versies als plugin voor Eclipse. Together werd gebruikt om de meeste
diagrammen te realiseren die in de loop van het project werden gecreëerd.
Meer info: http://www.borland.com/us/products/together
Javadoc is
een software tool die ontwikkeld werd door SUN. Javadoc wordt gebruikt om
API-documentatie te genereren in een HTML-formaat op basis van bepaalde tags
die een ontwikkelaar in de code verwerkt. Javadoc is de industriestandaard om
java-klassen te documenteren. Binnen Eclipse zit Javadoc ingebed.
Javadoc
werd samen met Together gebruikt om de klassestructuur en de UML-diagrammen van
de applicatie in HTML te genereren. Het
resultaat is te bekijken op de CD-rom in bijlage.
Meer info: http://java.sun.com/j2se/javadoc
Skype is
een peer-to-peer netwerk voor internettelefonie. De Skype client die toegang
geeft tot het netwerk is gratis te downloaden. Deze technologie maakt voor
gebruikers mogelijk om goedkoop met elkaar te bellen over het internet.
Deze technologie
werd gebruikt tijden de ontwikkeling van het project om met elkaar te
overleggen, problemen te bespreken en de GSM-kosten te beperken J.
Meer info: http://www.skype.com
JavaServer Pages
(JSP) is een Java technologie die het mogelijk maakt om server-side dynamisch
HTML, XML of andere webdocumenten te genereren nadat een gebruiker via zijn
webbrowser aan een webserver om een bepaalde pagina heeft gevraagd. De
JSP-technologie laat toe om Javacode of bepaalde JSP-tags in een statische
webpagina te integreren en er op die manier dynamisch gegenereerde inhoud aan
toe te voegen.
De meest
aangewezen manier van werken met JSP zijn de JSP-tags. Hierbij worden speciale
XML-tags toegevoegd aan een pagina met bijvoorbeeld HTML, die een bepaalde
bijhorende actie oproepen. Het voordeel van deze manier van werken is dat er
een mooie scheiding kan gemaakt worden tussen de presentatielaag en de applicatielaag.
JSP beschikt over een standaard-taglibrary die toelaat om standaardacties uit
te voeren. Het is echter ook mogelijk om zelf taglibraries te ontwerpen of om
een beroep te doen op taglibraries van derden om bepaalde specifieke
functionaliteiten toe te voegen. De JenkovTree taglibrary en de Display-Taglibrary
zijn voorbeelden van dergelijk taglibraries.
Als een
request naar een bepaalde JSP-pagina wordt gelanceerd, wordt de JSP-pagina
eerst in een servlet gecompileerd door een JSP-compiler. Deze compiler
genereert ofwel een servlet in JAVA-code, die dan op zijn beurt door de
JAVA-compiler wordt gecompileerd, ofwel genereert de JSP-pagina onmiddellijk de
servlet bytecode.
Voorbeeld
van het gebruik van de if- tag uit de JSP standard taglibrary:
|
<%@ page language="java"%>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core"
prefix="c"%>
<%@ page import=" be.vrt.cr.user.model.ClienBean"%>
<html>
<head>
<title>Test
IF-tag</title>
</head>
<body>
<jsp :usebean
id="client" class=" be.vrt.cr.user.model.ClienBean "
/>
<c:if
test="client.age > 18 " >
Beste klant, u
bent ouder dan 18 jaar, dus u hebt toegang tot deze applicatie.
</c:if>
</body>
</html>
|
Meer info: http://java.sun.com/products/jsp/index.jsp
De Jenkov
Tree tag library is een open source tag library die kan gebruikt worden om een
boomstructuur te genereren binnen een webapplicatie die gebruik maakt van
JSP’s. Bovendien is het mogelijk om de opmaak van de boomstructuur zelf te gaan
bepalen. De ontwerper volgde bovendien het MVC-patroon bij de implementatie en
zorgde ervoor dat er de taglibrary makkelijk samen met Jakarta Struts kon
worden gebruikt.
Meer info: http://www.jenkov.com
De Display
tag library is een open source library die het presenteren, sorteren, pagineren
en exporteren van gegevens die zich in een tabel bevinden, vereenvoudigt. De
versie waarvan gebruik werd gemaakt is terug te vinden op http://displaytag.sourceforge.net/10/.
Deze
taglibrary werd binnen de applicatie gebruikt om in de back-office de tabel
waarin reacties worden weergegeven vorm te geven, te pagineren en te sorteren.
Voorbeeld:
|
<%@ page language="java"%>
<%@
taglib uri="http://displaytag.sf.net" prefix="display"
%>
<% request.setAttribute(
"test", new TestList(10, false) ); %>
<display:table
name="test">
<display:column property="id" title="ID" />
<display:column property="name" />
<display:column property="email" />
<display:column property="status" />
<display:column property="description"
title="Comments"/>
</display:table>
|
Resultaat:
JCaptcha staat voor Java Completely
Automated Public Test to tell Computers and Humans
Apart. Het is
een stukje software dat in een JAVA-applicatie kan gebruikt worden om
applicaties te beschermen tegen scripting.
JCaptcha
laat toe om een afbeelding te genereren met daarop een combinatie van letters,
bijvoorbeeld op de eerste pagina van een applicatie die publiek toegankelijk is
via het internet. De onderstaande afbeelding is hier een voorbeeld van.
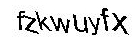
Van de
gebruiker van de applicatie wordt gevraagd om de lettercombinatie te
reproduceren in een invoervak. Vervolgens kan gecontroleerd worden of de code
op de afbeelding en de code in het invulvak gelijk zijn. Op deze manier kan
verhinderd worden dat externe programma’s toegang krijgen tot de applicatie. De
tekens op de afbeelding kunnen door deze programma’s immers moeilijk worden
uitgelezen.
Binnen de
applicatie werd deze techniek gebruikt om te verhinderen dat er automatisch
gegenereerde boodschappen in de databank zouden terecht komen.
Sitemesh is
een framework dat kan gebruikt worden om de opmaak van webpagina’s van een
(omvangrijke) website op een éénvoudige manier te uniformiseren. Indien een
client een request naar de webserver stuurt voor een statische of dynamische
webpagina zal Sitemesh dit onderscheppen. Sitemesh zal de pagina parsen, de
inhoud van de pagina ophalen en vervolgens een bepaalde opmaak toepassen op de
opgehaalde inhoud. Eventueel eerder gedane opmaak kan hierbij worden aangepast.
Deze manier van werken is gebaseerd op het decorator patroon.
SiteMesh is
opgebouwd met JAVA 2 en maakt gebruik van Servlet-, JSP- en XML-technologie.
Het is geschikt om gebruikt te worden in
een J2EE omgeving.
Sitemesh
werd binnen de applicatie gebruikt om een gemeenschappelijke vormgeving toe te
passen op de JSP-pagina’s. Header, Footer, CSS en algemene Javascripts worden
via Sitemesh aan elke JSP-pagina gekoppeld.
Meer info: http://www.opensymphony.com/sitemesh
HTML staat
voor Hypertext markup language en is de standaard markuptaal voor webpagina’s
die kunnen weergegeven worden binnen een webbrowser. HTML maakt gebruik van
tags om structuur, hoofdingen, paragrafen, lijsten enz. en grafische opmaak te
geven aan een webpagina.
HTML werd
in de presentatielaag zowel in de front-office als in de back-office gebruikt
om de gegevens weer te geven, op te maken en deels te positioneren door middel
van tabellen.
CSS staat
voor Cascading Style Sheets en kan gebruikt worden om de presentatie te bepalen
van gegevens die vervat zitten in een document die door middle van een bepaalde
opmaaktaal (HTML, XML) is opgemaakt. De CSS-specificatie wordt door het World
Wide Web Consortium beheerd.
In
vergelijking met de opmaakmogelijkheden van standaard HTML heeft CSS het
voordeel dat alle aspecten in verband met opmaak (fonts, kleuren,
positionering,…) kunnen beheerd worden vanuit één centrale stylesheet. Dit
maakt het mogelijk om de opmaak van de webpagina’s snel en eenvoudig aan te
passen.
CSS werd
gebruikt voor de opmaak van alle webpagina’s binnen de applicatie. Er werd één
centraal stylesheetdocument aangemaakt dat aan alle webpagina’s werd gelinkt.
Er werd
voor geopteerd om gebruik te maken van de mogelijkheid van CSS om de
verschillende onderdelen van de webpagina te positioneren. In vergelijking met
positionering via tabellen levert dit immers meer flexibiliteit op om de grote
blokken (bijvoorbeeld de menubalk of de navigatiebalk) van een webpagina te
positioneren. Om structuur te geven binnen deze blokken werd wel gebruik
gemaakt van tabellen.
Het
CSS-bestand is te vinden in de map styles van de webroot van de applicatie.
Javascript
is de naam die de Netscape Communication’s Corporation meegaf aan haar
implementatie van ECMAscript. Deze taal wordt voornamelijk gebruikt om binnen
een browser client-side scripting te doen en is op dit vlak de standaard.
Afhankelijk van browser tot browser bestaan er echter wel varianten. Binnen
Internet Explorer wordt er immers niet gewerkt met Javascript, maar met
JScript, wat de Microsoftimplementatie van ECMAscript is. Javascript is echter
de meest gebruikte term.
Binnen de
applicatie wordt Javascript voornamelijk gebruikt voor client-side controles
van formulieren. Ook wordt het gebruikt om bepaalde functionaliteiten van de
GUI mogelijk te maken zoals het uit en inklappen van een tree. Niet alle
Javascript die in de applicatie wordt gebruikt werd handmatig geschreven. Een
deel van de gebruikte Javascript, voornamelijk voor de controle van
formulieren, werd automatisch gegenereerd door Struts. Meer specifieke
javascripts voor specifieke controles of acties werden wel zelf geschreven.
Het
js-bestand met alle zelfgeschreven scripts is te vinden in de map scripts van
de webroot van de applicatie.
Extensible Stylesheet Language Transformations,of XSLT,
is een taal die op XML gebaseerd is en die gebruikt wordt voor de transformatie
van XML documenten in HTML of gewone tekst. XSLT veranderd op zich niets aan
het XML-document waarmee het wordt gecombineerd. Het genereert eerder een nieuw
document met een bepaalde vormgeving op basis van de inhoud die aanwezig is in
het XML-document.
XSLT werd
in de applicatie gebruikt om de tabbladstructuur van de back-office te
genereren op basis van een configuratiefile die aan de verschillende
gebruikersrollen toelaat om verschillende webpagina’s te bekijken.
Het
xslt-bestand dat zorgt voor de vormgeving van de tabs is te vinden in de map
xsl van de webroot van de applicatie.
eXtensible
Markup Language (XML) is een standaard voor het definiëren van formele
markup-talen voor de representatie van gestructureerde gegevens in de vorm van
platte tekst. De inhoud van de gegevens is die gestructureerd worden speelt
hierbij geen rol. Allerlei verschillende types informatie kunnen met XML van
een structuur voorzien worden. XML is een manier om data te beschrijven, maar
kan ook de data bevatten, zoals in een databank. XML kan dus ook gebruikt
worden om gegevens in op te slaan.
De eerste
doelstelling van XML is het delen van informatie tussen verschillende systemen,
in het bijzonder tussen systemen die via het Internet met elkaar verbonden
zijn. XML wordt echter ook vaak gebruikt om configuratie informatie in op te
slaan.
In de
applicatie wordt XML in de verschillende lagen als configuratiefile gebruikt
(Hibernate, Struts, SiteMesh, configuratiefile van de gebruikerstabs).
Het
xml-bestand met daarin de gegevens waarop de weergave van de tabs gebaseerd is,
is te vinden in de map xml van de webroot van de applicatie.
Voor een
uitgebreide bespreking van het Struts Framework en het Struts
configuratiebestand kan men terecht in onderdeel van dit verslag in verband met
het ontwerp van de klassestructuur.
Voor een
uitgebreide bespreking van de structuur van het businesmodel kan men terecht in
onderdeel van dit verslag in verband met het ontwerp van de klassestructuur.
Voor een
uitgebreide bespreking van het Hibernate Framework en het Hibernate
configuratiebestand kan men terecht in onderdeel van dit verslag in verband met
het ontwerp van de structuur van de databank.
MYSQL is
een Relationeel database managementssysteem dat multithreading ondersteunt en
door vele gebruikers tegelijk kan worden ingezet. Het aantal installaties wordt
geschat op zes miljoen. MYSQL dankt zijn populariteit aan het feit dat het
gratis te downloaden is en kan gebruikt worden vanuit een brede waaier van
programmeertalen, waaronder C, C++, C#, Eiffel, Smalltalk, Java, Lisp, Perl,
PHP, Python, Ruby, REALbasic etc en is beschikbaar voor verschillende
bestuurssystemen. Vooral de combinatie van MYSQL met PHP, draaiend op een LINUX
machine is erg populair. Ook is er een ODBC interface voor MYSQL beschikbaar.
Bovendien is MYSQL een erg krachtige database die niet moet onderdoen voor zijn
betalende concurrenten.
De
administratie van MYSQL kan vanaf de command line gebeuren, maar er werden ook
tools ontwikkeld met een grafische user interface. MySQL Administrator wordt
gebruikt voor alle administratieve taken zoals het aanmaken van de databases,
het maken van backups, gebruikersadministratie enz. Voor het uitvoeren van
Queries werd MySQL Query Browser ontwikkeld. Beide tools zijn gratis te
downloaden van de MYSQL website.
Tijdens het
project werd dankbaar gebruikt gemaakt van de combinatie van MYSQL met de twee
administratieve tools. Het leek ons een goede keuze omwille van de kwaliteit
van de database, het gebruiksgemak en het feit dat men binnen VRT met succes
van deze database gebruik maakt.
In wat
volgt zal eerst de functionaliteit van de Front-Office worden besproken om
vervolgens in te gaan op de functionaliteit van de Back-Office. De bespreking
van de functionaliteit gebeurt aan de hand van enkele screenshots.
Het Front
Office bestaat uit een module om reacties van klanten over de verschillende
netten van VRT (Een, Canvas, Ketnet, Sporza) en hun programma’s te registreren.
De module, waarvan de opmaak makkelijk aanpasbaar is, laat de klant toe om zijn
klacht in vijf stappen te registreren.
Bovenaan de
module bevindt zich de navigatiebalk, die aangeeft in welke stap van de
registratieprocedure de klant zich bevindt. Links van de module bevindt zich
een helptekst die de gebruiker meer informatie biedt over hetgeen wat in de
stap van hem verwacht wordt. In het rechtervak bevindt zich het eigenlijke
invulformulier.
De
onderstaande afbeelding illustreert deze structuur.

In de
eerste stap kan de klant zijn persoonlijke gegevens (naam, voornaam, email)
registreren. Daarnaast moet de klant de code die op de JCaptcha-afbeelding
staat overnemen in het invulvak code. Nadat alle informatie is ingevuld kan de
klant op de knop onderaan de pagina klikken om naar stap 2 over te gaan.
In stap 2
kan zijn reactie verder omschrijven. Hij kan dat doen door een type te
selecteren (vraag, reactie, felicitatie, suggestie, klacht) en een categorie.
De categorie kan op verschillende niveaus toegekend worden. Het eerste niveau
is dat van het net, het tweede niveau is dat van het programma. Vanaf het derde
niveau zullen programmagebonden niveaus aan de klant gepresenteerd worden die
kunnen verschillen van programma tot programma. Telkens er een keuze wordt
gemaakt op een bepaald niveau zal er nagegaan worden of er zich nog een
dieperliggend niveau bevindt. Indien dat zo is, zal dat in een nieuwe klapbox
worden getoond. Een klik op de knop onderaan de pagina brengt de klant naar de
volgende stap.

In stap
drie kan de klant kiezen uit twee mogelijkheden. Indien er standaardantwoorden
voor de geselecteerde categorie beschikbaar zijn zullen deze op dit scherm
worden gepresenteerd onder de FAQ rubriek. De klant kan op de FAQ’s klikken en
zo de standaardantwoorden op het scherm tonen.
Indien er
geen FAQ’s voorhanden zijn, of indien de klant in de FAQ’s geen antwoord vindt
op zijn vragen, kan de klant zelf een reactie formuleren. In het titelvak kan
hij een titel aan de reactie toekennen. In het vak boodschap kan hij de
eigenlijke reactie formuleren.
Nadat de
reactie geformuleerd is, kan door op de knop ‘Stap 4’ te klikken naar de
volgende pagina worden overgegaan.
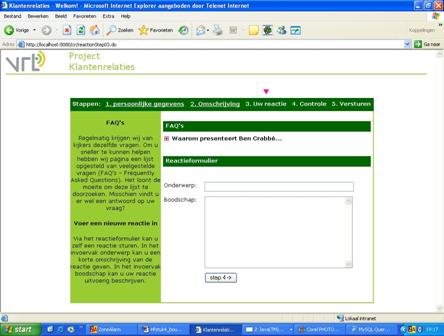
In deze
stap krijgt de klant een overzicht van alle informatie die eerder werd
ingevoerd. De klant kan hier nagaan of alle ingevoerde informatie correct is.
Indien dat
zo is, kan hij naar de volgende stap gaan door op de knop ‘Stap 5’ te klikken.
Indien er
nog zaken moeten worden aangepast, kan de klant door middel van de links op de
navigatiebalk bovenaan naar één van de vorige pagina’s navigeren.
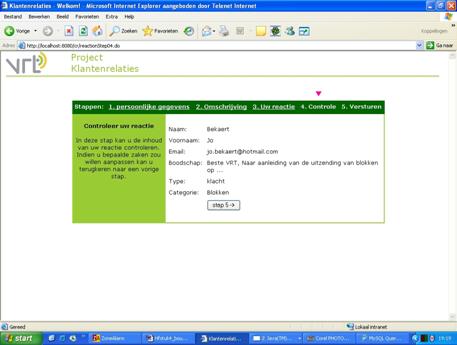
In de
laatste stap wordt de reactie van de klant geregistreerd in het systeem. Er
wordt een boodschap weergegeven om aan te geven dat de registratie geslaagd is.
De back
office verzamelt alle functionaliteit voor het beheer van de door klanten
gegeven reacties door de medewerkers van VRT.
De
interface bestaat uit een aantal onderdelen die steeds terug komen. Bovenaan de
pagina staat steeds de banner van het project. In de linkerkolom van de pagina
staan respectievelijk de gegevens van de gebruiker en de systeemmanager. De
invulling van de systeemmanager kan van pagina tot pagina verschillen. De ene
keer worden de filtermogelijkheden van de boodschappen hier ondergebracht, de
andere keer de boomstructuur van de standaardantwoorden. In de rechterkolom van
de pagina staan respectievelijk de menubalk met tabs om door te klikken naar de
verschillende onderdelen van de applicatie en het inhoudelijk onderdeel. In het
inhoudelijk onderdeel kan men ofwel informatie bekijken, zoals de lijst met boodschappen
ofwel kan men er informatie invoeren.
De
onderstaande afbeelding stelt deze structuur visueel voor.
Dit
onderdeel van de applicatie geeft aan de gebruiker een overzicht van de boodschappen
die hij moet beheren. Er worden maximaal 100 boodschappen tegelijkertijd uit de
database opgehaald. De gebruiker krijgt steeds een aantal kerngegevens in
verband met de boodschap te zien, zoals de afzender, de titel, de categorieën,
de datum etc. De boodschappen kunnen steeds gesorteerd worden op elk van de
kerngegevens door op het hoofdterm van de betreffende kolom te klikken. Links
van de pagina bevindt zich in de servicemanager een filter. Deze kan gebruikt
worden om een selectie te maken in de boodschappen. Er kan gefilterd worden op
status, prioriteit, type, datum en categorie. Als men uit de lijst van
categorieën een term selecteert zal automatisch worden nagegaan of er voor de
geselecteerde categorie nog een lijst met subcategorieën bestaat. Indien dat
het geval is zal er een extra klapbox met de lijst van subcategorieën worden
toegevoegd. Indien men uit deze nieuwe klapbox een selectie maakt zal dit
proces herhaald worden.
De boodschappen
worden in blokken van 15 weergegeven op één pagina. Er werd in een mechanisme
voorzien om doorheen de verschillende boodschappen te kunnen bladeren. Indien
de gebruiker een boodschap in detail wenst te bekijken kan hij dat doen door op
het icoon te klikken dat zich vooraan elke boodschap-rij bevindt.
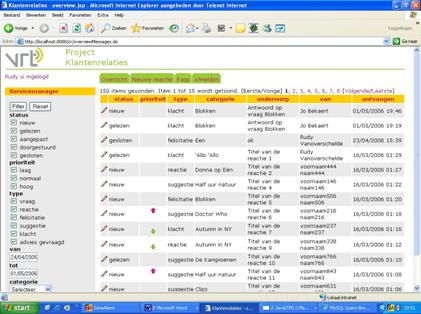
De
detailweergave van een reactie bevat twee modules die op de pagina in het
inhoudelijke blok gesitueerd zijn. Een eerste module geeft de geschiedenis van
de reactie weer. Deze geschiedenis houdt de originele reactie van een klant in,
aangevuld met alle acties die er na ontvangst op de reactie gebeurden, zoals
leesacties, vragen voor advies, overdrachten enz. Ook is het mogelijk om in
deze module een aantal zaken aan te passen, zoals de prioriteit van de reactie
en het type.
De tweede
module is bedoeld om een aantal bewerkingen op de reactie uit te voeren. Deze
laat toe om reacties te beantwoorden, op te volgen, advies te vragen, door te
sturen en af te sluiten. Afhankelijk van de selectie die men maakt zullen er
bepaalde extra functionaliteiten op het scherm worden getoond. Als men
bijvoorbeeld kiest om een advies te vragen over een bepaald antwoord, zal er
een klaplijstje verschijnen met daarin de laatste tien e-mailadressen waarnaar
een vraag voor advies werd verstuurd. Een andere functionaliteit die verschijnt
is een invoervak waarin men een eigen standaard-signatuur (naam – adres etc.)
kan toevoegen en eventueel aanpassen.
De
servicemanager bevat een lijst van standaardantwoorden die relevant zijn voor
de categorie waarin het antwoord zich bevindt. Een klik op één van de titels in
de lijst vult het antwoord automatisch in in het invoervak. Dit maakt het
eenvoudig om een reactie te beantwoorden met een standaardantwoord.
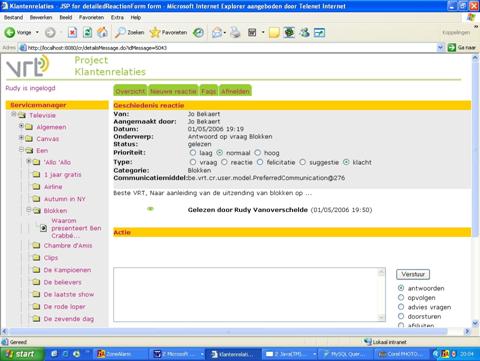
Indien een
medewerker, als hij werkt in de detailweergave van een reactie, het antwoord op
een bepaalde reactie niet onmiddellijk kent, kan hij advies inwinnen bij een
andere medewerker van VRT. Dit kan op twee manieren.
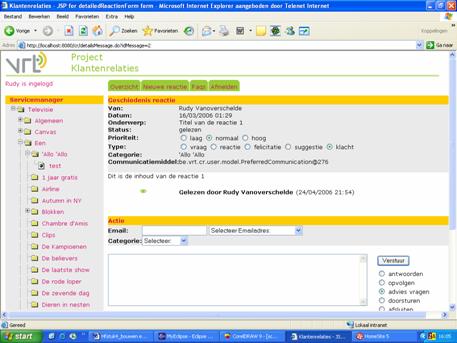
De eerste
manier is advies vragen aan iemand intern die ook met het systeem werkt. In zo’n
geval volstaat het om in de lijst van categorieën de juiste categorie te
selecteren van de dienst of programmamaker die mogelijk het juiste antwoord
kent en dan de vraag om advies te versturen. De persoon of dienst waaraan
advies wordt gevraagd zal dan de vraag om advies in zijn lijst met reacties
zien verschijnen. Vervolgens kan hier door hem op gereageerd worden.
Een tweede
manier van werken is nuttig indien men de vraag om advies via email wenst te
stellen. In een dergelijk geval kan in het vak email een emailadres worden
ingevuld. Als men vervolgens op versturen klikt, zal de vraag om advies via
e-mail verstuurd worden naar het e-mailadres dat werd ingevuld. De persoon aan
wie de vraag om advies gericht is, zal dan in zijn mailbox de vraag om advies
vinden, samen met een hyperlink naar de applicatie. Als hij hierop klikt zal
hij via zijn webbrowser avies kunnen geven over de reactie door middel van een
online formulier. Het advies zal na versturen geregistreerd worden in de
databank van de applicatie.
De
mogelijkheid bestaat dat een medewerker zelf een nieuwe reactie moet
registreren. Bijvoorbeeld als een reactie telefonisch wordt gegeven. Het
registreren van een dergelijke reactie kan via deze module.
In het
inhoudelijke blok bevinden zich twee modules. Een eerste module is bedoeld voor
het opzoeken en registreren van de persoonlijke gegevens van de klant. De
medewerker kan in het invulformulier de naam van een klant, zijn voornaam,
adres, telefoonnummer etc. invoeren.
Als de
medewerker wilt opzoeken of de klant al eerder werd geregistreerd kan dat. Een
klik op de knop “zoek klant” levert in de servicemanager een lijst op van alle
eerder geregistreerde klanten waarvan de gegevens overeenkomen met de tot dan
toe ingevulde gegevens in het formulier. Op die manier kan er snel worden
nagegaan of de klant al eerder geregistreerd werd. Als men vervolgens in de
servicemanager klikt op één van de verschenen namen in de servicemanager,
zullen de gegevens van de aangeklikte klant (naam, voornaam, telefoonnummer,
adres etc.) automatisch in het invulformulier worden ingevuld.
De tweede
module dient om de reactie zelf te omschrijven. Er kan een type, een categorie,
een prioriteit een titel en uiteindelijk de reactie zelf worden geregistreerd.
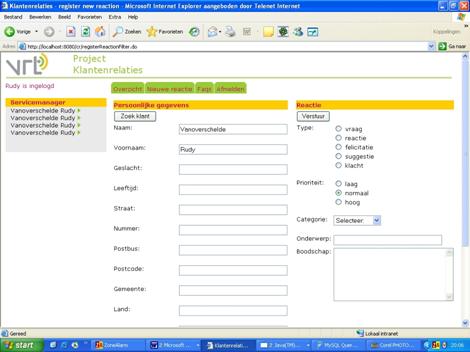
De
applicatie laat toe om voor elke item in de structuur van programmacategorieën
standaard-antwoorden te registreren. Deze worden gebruikt door de medewerkers
van VRT om sneller te kunnen antwoorden op veel voorkomende vragen. Daarnaast kunnen
standaard-antwoorden ook gepubliceerd worden op het internet zodat de klanten
in de front-office de Frequently Asked Questions kunnen raadplegen.
De
gebruiker van de applicatie kan enkel standaard-antwoorden toekennen aan de
categorieën waarvoor hij bevoegd is. Andere categorieën zijn zichtbaar in de
servicemanager maar niet aanklikbaar. Als de medewerker een categorie aanklikt
zal de boom van categorieën openklappen. Tegelijkertijd zal er in het
inhoudelijk blok een formulier verschijnen waarin een standaard-antwoord met
een bepaalde titel kan worden ingevuld. Als men in het formulier een standaard-antwoord
invult kan men het registreren door op de knop “registreer FAQ” te klikken. Het
standaard-antwoord zal dan verschijnen in de boomstructuur op het juiste
niveau.
Als men op
het nieuw verschenen standaard-antwoord klikt kan men het verder gaan beheren
door middel van de nieuwe functies die in het inhoudelijk blok verschijnen. Men
kan de inhoud en de titel aanpassen, men kan het antwoord verwijderen en men
kan het antwoord publiek maken. Dit laatste houdt in dat men een standaard-antwoord
beschikbaar maakt binnen de front office voor de klanten. Als men het antwoord niet publiek maakt is
het standaard-antwoord enkel zichtbaar voor diegenen die de front-office
gebruiken. Niet alle medewerkers beschikken over dezelfde functionaliteit.
Slechts enkele medewerkers hebben het recht om de standaard-antwoorden publiek
te maken.
Een
belangrijke systeemvereiste was het verwerken van een groot aantal boodschappen
en gebruikers. We hebben hiermee
gedurende het hele ontwerp en de ontwikkeling rekening gehouden. In de applicatie zelf wordt zo weinig
mogelijk gecached en zo veel mogelijk de persistentielaag (Hibernate)
aangesproken. Zo blijft het
geheugengebruik per sessie beperkt.
Hierdoor
kan de applicatie ook eventueel geoptimaliseerd worden door bijvoorbeeld een
level2 cache in Hibernate te integreren.
Veel gebruikte objecten kunnen dan over de sessies heen worden gecached. Omdat we slechts één session-factory gebruiken,
zouden de objecten in de level2-cache een applicatie-scope hebben. Hibernate laat toe de gewenste soort caching
te regelen op het niveau van objecten, associaties en queries.
Om de
performantie van de persistentielaag te testen hebben we de database gevuld met
realistische aantallen voor de klanten, medewerkers, boodschappen en
categorieën. Vooral de tabellen klanten
en boodschappen zullen door hun omvang problemen geven bij het opvragen van
data. De moeilijkste query in onze
applicatie is ongetwijfeld diegene die een overzicht van de boodschappen
opvraagt:
·
Er
moet gesorteerd worden op datum
·
Er
moet gefilterd worden op rechten voor de gebruiker (koppeling over
verschillende tabellen)
·
Er
moet gefilterd worden op status, prioriteit, type, datum en categorie
(koppelingen met verschillende tabellen)
·
Van
elke boodschap moeten de namen van de afzender, status, type, prioriteit en
categorie worden getoond (initialiseren van de lazy-fetching -> koppeling
met verschillende tabellen)
·
Het
aantal opgevraagde boodschappen moet gelimiteerd worden.
Een
uitdaging J.
Onderstaande
toont de niet geoptimaliseerde HQL-query die we tijdens de ontwikkeling gebruikten.
public static List getMessages(MessageFilter myMF, User myUser) throws
MessageException {
try{
StringBuffer sb = new
StringBuffer("select m from Message m ");
sb.append("join fetch m.state s
");
sb.append("join fetch m.priority p
");
sb.append("join fetch m.type t
");
sb.append("join fetch m.sender
");
sb.append("join fetch m.category c
");
sb.append("join c.privileges priv
");
sb.append("where priv.employee =
:user ");
sb.append("and s.name in (:selectedStates) ");
sb.append("and p.name in (:selectedPriorities) ");
sb.append("and t.name in (:selectedTypes) ");
sb.append("and m.timeRecieved between :startDate and
:endDate ");
if( !
myMF.getId().equals("C1") ) {
sb.append("and c.idCategory =
(:id)");
}
sb.append("order by m.timeRecieved
desc");
Session mySession =
HibernateSessionFactory.currentSession();
Transaction tx = mySession.beginTransaction();
Query myQuery =
mySession.createQuery(sb.toString());
myUser = (Employee) myUser;
myQuery.setEntity("user",myUser);
myQuery.setParameterList("selectedStates",
myMF.getSelectedStates());
myQuery.setParameterList("selectedPriorities",
myMF.getSelectedPriorities());
myQuery.setParameterList("selectedTypes",
myMF.getSelectedTypes());
myQuery.setTimestamp("startDate", myMF.getStartDate());
myQuery.setTimestamp("endDate", myMF.getEndDate());
if( !
myMF.getId().equals("C1") ) {
Integer id = new
Integer(myMF.getId().substring(1));
myQuery.setInteger("id",
id.intValue());
}
myQuery.setMaxResults(150);
log.debug("start- and endDate
query: ");
log.debug( myMF.getStartDate() );
log.debug( myMF.getEndDate() );
List messages = myQuery.list();
tx.commit();
HibernateSessionFactory.closeSession();
return messages;
}
catch(Exception e){
throw new
MessageException("Cannot load the messages from the database", e);
}
}
Deze query (zonder
optimalisatie) geeft onderstaande responsetijden.
|
#
messages
|
#
employees
|
#
clients
|
tijd
|
|
5000
|
5
|
1000
|
< 2 sec
|
|
1700
|
1000
|
60000
|
15 sec
|
|
60000
|
1000
|
60000
|
4 min 10 sec
|
De aangegeven tijd is gemeten tussen de http-request en de http-response
in een ontwikkelomgeving (gewone pc - trage disk - geen RAID).
Uiteraard
is meer dan 4 minuten wachten op het resultaat niet aanvaardbaar.
Vervolgens
hebben we de query opgedeeld in verschillende delen en telkens de impact op de
performantie bekeken. Door de grootste
cartesiaanse producten (bijvoorbeeld de koppeling tussen de tabellen users en
messages) te vermijden verkregen we onderstaand resultaat.
|
#
messages
|
#
employees
|
#
clients
|
Tijd
|
|
60000
|
1000
|
60000
|
25 sec
|
De aangegeven tijd is gemeten tussen de http-request en de http-response
in een ontwikkelomgeving (gewone pc - trage disk - geen RAID).
Het snelste
resultaat hebben we bekomen door de query voor het eigenlijke ophalen van
boodschappen volledig af te zonderen en dus niet te koppelen met andere tabellen. Onderstaand stukje code toont de queries voor
het beste resultaat.
public static List getMessages(MessageFilter myMF, User myUser) throws
MessageException {
try{
StringBuffer sb01 = new
StringBuffer("select c from Category c ");
sb01.append("join c.privileges
priv ");
sb01.append("where priv.employee =
:user ");
StringBuffer sb02 = new
StringBuffer("select s from State s ");
sb02.append("where s.name in (:selectedStatesNames) ");
StringBuffer sb03 = new
StringBuffer("select p from Priority p ");
sb03.append("where p.name in (:selectedPrioritiesNames) ");
StringBuffer sb04 = new
StringBuffer("select t from Type t ");
sb04.append("where t.name in (:selectedTypesNames) ");
StringBuffer sb05 = new
StringBuffer("select m from Message m ");
sb05.append("where m.state in (:selectedStates) ");
sb05.append("and m.priority in (:selectedPriorities) ");
sb05.append("and m.type in (:selectedTypes) ");
sb05.append("and m.timeRecieved between :startDate and
:endDate ");
if(
! "C1".equals(myMF.getId()) ) {
sb05.append("and
m.category.idCategory in (:idCategory) ");
}
sb05.append("and m.category in
(:myCategories) ");
sb05.append("order by
m.timeRecieved desc");
Session mySession =
HibernateSessionFactory.currentSession();
Transaction tx = mySession.beginTransaction();
Query myQuery01 =
mySession.createQuery(sb01.toString());
myUser = (Employee) myUser;
myQuery01.setEntity("user",myUser);
List myCategories = myQuery01.list();
tx.commit();
Query myQuery02 =
mySession.createQuery(sb02.toString());
myQuery02.setParameterList("selectedStatesNames",
myMF.getSelectedStates());
List myStates = myQuery02.list();
tx.commit();
Query myQuery03 =
mySession.createQuery(sb03.toString());
myQuery03.setParameterList( "selectedPrioritiesNames",
myMF.getSelectedPriorities());
List myPriorities = myQuery03.list();
tx.commit();
Query myQuery04 =
mySession.createQuery(sb04.toString());
myQuery04.setParameterList("selectedTypesNames",
myMF.getSelectedTypes());
List myTypes = myQuery04.list();
tx.commit();
Query myQuery05 =
mySession.createQuery(sb05.toString());
myQuery05.setTimestamp("startDate", myMF.getStartDate());
myQuery05.setTimestamp("endDate", myMF.getEndDate());
myQuery05.setParameterList("selectedStates", myStates);
myQuery05.setParameterList("selectedPriorities",
myPriorities);
myQuery05.setParameterList("selectedTypes", myTypes);
if(
! "C1".equals(myMF.getId()) ) {
Integer
id = new Integer(myMF.getId().substring(1));
myQuery05.setInteger("idCategory",
id.intValue());
}
myQuery05.setParameterList("myCategories",
myCategories);
myQuery05.setMaxResults(100);
List messages = myQuery05.list();
tx.commit();
for(Iterator myIterator =
messages.iterator(); myIterator.hasNext(); ){
Message myMessage = (Message)
myIterator.next();
Hibernate.initialize(myMessage.getSender());
}
HibernateSessionFactory.closeSession();
return messages;
}
catch(Exception e){
throw new MessageException("Cannot load the messages from the
database", e);
}
}
Deze query
(met optimalisatie) geeft onderstaande responsetijden.
|
#
messages
|
#
employees
|
#
clients
|
tijd
|
|
60000
|
1000
|
60000
|
< 2
sec
|
|
100000
|
1000
|
60000
|
< 2 sec
|
De aangegeven tijd is gemeten tussen de http-request en de http-response
in een ontwikkelomgeving (gewone pc - trage disk - geen RAID).
Vier
queries worden vóór het zoeken naar de boodschappen uitgevoerd. Ze halen de objecten op die als filters zullen
worden gebruikt:
·
de
categorieën waarop de gebruiker rechten heeft
·
de
geselecteerde filter-statussen
·
de
geselecteerde filter-prioriteiten
·
de
geselecteerde filter-types
Via een
parameterlijst worden de “filters” in de query voor het ophalen van
boodschappen ingevuld. Door het
“in”-statement te gebruiken, zal Hibernate geen enkele koppeling maken met
andere tabellen. Hierna moet enkel nog per
message de naam en de voornaam van de afzender worden geinitialiseerd (lazy
fetching).
Tenslotte
hebben we ook een index gelegd op “timeRecieved” die in de “where” en
“order-by”-clausule worden gebruikt. Ook
deze ingreep bleek een grote invloed te hebben op de performantie.
Het zou misschien
nuttig zijn een clustered index voor dit veld te maken. Zo worden de boodschappen altijd fysiek in de
volgorde van “timeRecieved” opgeslagen (wat in normale omstandigheden meestal
automatisch zo is).
Uit deze
test blijkt de degelijkheid van Hibernate.
Het laat perfect toe ook moeilijke queries te optimaliseren.
Bij het
effectieve gebruik in omgeving met vele gebruikers laat de level2-cache een
verdere tuning van de applicatie toe.
|
Coupling van
de objecten
|
Commentaar bij
de code
|
|
- Het aantal klasses waarmee een klasse gekoppeld
is. Telt het aantal reference-types
dat gebruikt wordt in attribuut-declaraties, formele parameters,
return-types, throws-declaraties en lokale variabelen. Primitieve types, types van de
java.lang.package en supertypes worden niet meegerekend.
- default max 30
- toont per package de waarde van klasse met het
hoogste aantal
|
- Berekent de
verhouding tussen enerzijds de documentatie (Javadocs) en het commentaar bij
de code en anderzijds het aantal lijnen code
- default min 5
- toont per package de waarde van klasse met het
kleinste aantal
|
|
|
|
|
- Een hoge coupling is nefast
voor een modulair design en verhindert eenvoudig hergebruik van de
klasses. Hoe hoger het cijfer van de
coupling, hoe moeilijker het ook wordt de code te herwerken of te onderhouden. De coupling geeft ook een indicatie van de
complexiteit van het testen van de applicatie (hoe hoger, hoe moelijker).
-. De test-waardes liggen gemiddeld ver onder default
maximum van 30
- Eén
uitschieter van 38 is de klasse DetailsReactionAction in het pakket
be.vrt.message.web .
Controller-klasses zoals de Action-klasses in Struts, zijn typisch
klasses die veel gebruik maken van andere klasses. De hoge waarde van de complexe
DetailsReactionAction-klasse moet dan ook wat worden gerelativeerd.
|
- Er bestaan verschillende visies over het documenteren
van de code met javadoc. Sommige
vinden dat de code voor zich moet spreken en dat commentaar of javadocs de
code “bevuilen”.
- Persoonlijk ben ik er echter van overtuigd dat
documentatie een vorm van communicatie is.
Javadocs spelen een belangrijke rol bij het begrijpen van de
functionaliteit van klasses en dus bij het herwerken of onderhouden van een
applicatie. Het is een soort contract
tussen diegene die een klasse wil gebruiken en diegene die ze maakt.
- Reeds bij de OO-ontwerp-fase werden geregeld javadocs
en commentaar toegevoegd. Dit maakte
het invullen van de functionaliteit gemakkelijker
- De hoge waardes zijn soms enigszins vertekend door
kleine klassen die in verhouding veel overhead aan commentaar hebben
(exceptie-klasses)
|
|
Aantal
attributen
|
Aantal
operaties
|
|
- Telt het aantal attributen.
- default max 30.
- toont per package de waarde van klasse met het
hoogste aantal.
|
- Telt het aantal operaties
(methodes die overruled worden zijn niet meegeteld).
- default max 50.
- toont per package de waarde van klasse met het
hoogste aantal.
|
|
|
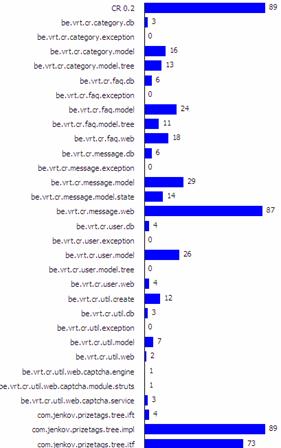
|
|
- Klassen met veel atributen kunnen soms beter in
kleinere klassen worden op gedeeld.
- De uitschieter in deze grafiek is de klasse
RegisterReactionForm in de package be.vrt.cr.message.web. ActionForm zoals deze klasse worden
gebruikt om waardes tussen de ‘view’ en het ‘model’ te transporteren. Bij struts worden vaak grote ActionForms
gebruikt voor verschillende Actions (delen van de business-logica). Hier gaat het echter over veel informatie
die van en naar het detailscherm van een reactie moet worden getransporteerd.
- De andere klasses liggen allen ver onder het maximale
streefdoel
|
- Klassen met veel operaties kunnen soms beter in
kleinere klassen worden op gedeeld.
- De uitschieter hier is dezelfde als bij de test voor
het aantal attributen. Het hoge getal
heeft enkel te maken met de get- en setfuncties van die klasse.
- De andere klassen liggen allen ver onder het maximale
streefdoel
|
|
Diepte van de
inheritance
|
Diepte van de
lussen (if, for, while)
|
|
- Telt de lengte van de inheritance van de ‘root’ naar
een specifieke klasse.
- Default max 5.
- Toont per package de waarde van klasse met het hoogste
aantal.
|
- Telt de diepte van de lussen
(if, for, while) in de methods van een klasse.
- Default max 7.
- Toont per package de waarde van klasse met het
hoogste aantal.
|
|

|
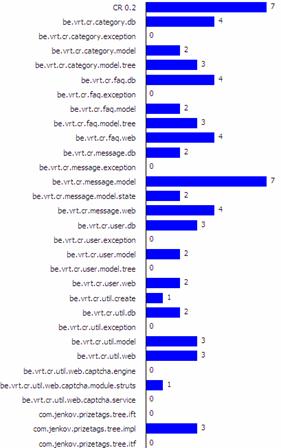
|
|
- In een OO-ontwerp is inheritance een sleutel-element
waarvan zeker gebruik moet gemaakt worden.
Inheritance gebruiken moet echter ook functioneel zijn. Een complexe inheritance-structuur kan
casting-problemen geven. Het gebruik
van de functie ‘instanceof’ om de afgeleide klasse te bekomen, mag niet
zomaar overal in de applicatie worden gebruikt.
- Alle waardes liggen onder het maximale streefdoel.
|
- Methodes met een waarde
hoger dan 7 worden erg moeilijk om te begrijpen. Een vereenvoudiging van de implementatie
kan nuttig zijn.
- De hoogste waarde in de
applicatie is het default maximum.
|