|
Hoofdstuk 2 |
2.
Applicatie- en presentatie
laag
2.1.1.
Inleiding
2.1.1.1.
High
bit rate versus low bit rate
Video in een gewone PC-omgeving (het internet of LAN’s) betekent nog altijd iets totaal anders dan digitale video in een studio-omgeving. Streaming over het internet aan een snelheid van 300-500Kbps is een prestatie. De standaard studiointerface SDI (serial digital interface) gebruikt 270Mbps [1]. Nog steeds ongeveer een factor 1000 verschil. Maar high bit rates en low bit rates groeien naar elkaar toe en er ontstaan allerhande (tussenliggende) varianten die kwalitatief goed zijn. Betere coderingstechnieken zorgen voor deze evolutie.
Er bestaan veel verschillende
videoformaten. De meeste zijn echter
gebaseerd op een aantal basisprincipes.
Daarom lijkt het me interessant de principes te overlopen en daarna de
belangrijkste formaten op een rijtje zetten.
2.1.1.2.
Constant
quality (variable bit rate) versus constant bit rate.
Compressietechnieken kunnen twee soorten bitstreams voortbrengen. Zoals de naam doet vermoeden, levert een constant bit rate (CBR) coder een constante stroom bits op. Een nadeel is dat de kwaliteit niet constant is. Hoe complexer de info van het oorspronkelijke beeld, hoe groter de compressie moet zijn om binnen een vaste bitstroom te passen en hoe lager de uiteindelijke beeldkwaliteit zal zijn. Constant quality coding of variable bit rate (VBR) coding is het tegenovergestelde.
VBR is vooral interessant voor non-real-time-transfer (file-transfer) of opslagsystemen. Het voorbeeld hierbij is de DVD (digital versatile disk). CBR wordt meer gebruikt bij transmissie met vaste bandbreedtes.
In praktijk lopen VBR en CBR wat door elkaar. Sommige videoformaten werken met beiden, dikwijls wordt ook VBR beperkt door een maximum datarate en CBR werkt met buffers om de kwaliteit zo goed mogelijk te houden.
2.1.2. De principes
2.1.2.1. Overzicht
Verliesloze bitstroomreductie (videocompressie) is enkel mogelijk wanneer het beeld overtollige info bevat. Helaas is deze compressie meestal niet voldoende.
Compressie steunt op het algemene principe dat “nabije” pixels meestal niet veel van elkaar verschillen. Die nabije pixels kunnen zowel binnen 1 beeld gezien worden (intrabeeld) als tussen verschillende beelden (interbeeld).
Enkele typische basisprincipes van intrabeeld-compressie zijn samengevat in onderstaand blokdiagram: (de stappen met kwaliteitsverlies zijn aangeduid met * )
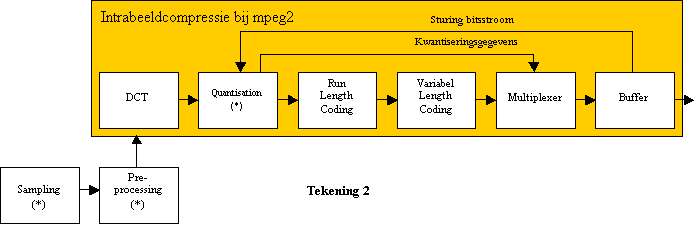
1. (*) Sampling: een beeld omzetten in beeldpunten (pixels)
2. (*) Preprocessing: de beeldinfo “klaarmaken” voor de compressie-eigenschappen
3. Discrete Cosinus Transformatie (DCT): een omzetting van video-informatie in een vorm die de volgende stappen mogelijk maken.
4. (*) Quantiseren: afrondingen veroorzaken informatieverlies vooral in de minder belangrijke videoinformatie (afhankelijk van het soort beeld)
5. Run Length Codering: gelijke waarden noteren als “n keer A” in plaats van “AAAAAAAAAAAAAA...A”
6. Variabele lengte Codering: waarden die vaak voorkomen kortere binaire codes geven dan waardes die minder vaak voorkomen (zoals de morse-code).
Buffers worden voorzien om de bitstroom te regelen. Dreigt het aantal bits bij de uitgang van het compressiesysteem te groot te worden, dan kan bijvoorbeeld stap 4 (de verliesfactor bij het quantiseren) tijdig worden aangepast om meer te comprimeren.
DCT wordt bij vele compressietechnieken gebruikt (zie 2.1.3 In de praktijk). Andere en nieuwere technieken zijn discrete wavelet coding (DWC) en edge based coding (objectgerichte compressie). Verschillende quantiseringsmethodes zijn scalar en vector-quantisering.
Interbeeld compressie wordt vooral gebruikt bij lage bitrates en dus bij grote compressie. Nadelen zijn de moeilijke nabewerking (vb. montage) en vertragingen. De beelden moeten bij de reconstructie berekend en/of gebufferd worden. Vaak worden enkel bewegingsvectoren en verschilcomponenten doorgestuurd. Bovendien wordt het aantal frames per seconde bij lage bitrates dikwijls beperkt tot 10 of 15.
Tot slot wordt alle nieuwe informatie gemultiplext om alles serieel te kunnen doorsturen.
Enkele van deze begrippen worden nu verder uitgewerkt.
2.1.2.2. Sampling
Bij de omzetting van analoog naar digitale video, wordt met een hoge frequentie (vb.13,5MHz [2]) de waarde van het videosignaal “gemeten”. Dit proces heet sampling en resulteert in een aantal, (bijvoorbeeld 720) pixels of samples per lijn. De gemeten samplewaarde wordt omgezet in een binaire code. Wanneer men 8 bits per sample gebruikt, kan de waarde met een precisie van 1/28 of 1/256 worden omgezet. Er treedt dus verlies op.
“Het aantal pixels per lijn, vermenigvuldigd met het aantal lijnen”, wordt vaak de resolutie genoemd. Een veel gebruikte resolutie binnen TV is 720*576. Bij PC-toepassingen wordt vaak gesproken over CIF (common intermediate format): 352*288 ; Q-CIF (quarter-CIF): 176*144 en 4*CIF: 704*576.
Een ander belangrijk begrip is de samplingstructuur. Ze bepaalt hoe de kleuren verwerkt worden.
In een digitale TV-omgeving werkt men met EY (helderheidcomponent), EY-R en EY-B ([3]). Meest gebruikt is de 4:2:2 techniek. De getallen 4, 2 en 2 duiden op de verhouding waarin respectievelijk de helderheidsamples en de samples van de kleurverschilsignalen voorkomen. (zie tekening 3). Er worden dus meer samples genomen voor de helderheid omdat het oog daar gevoeliger voor is. Ook 4:1:1 (zie tekening 4) en 4:4:4 structuren worden gebruikt.
Tekening 4 4:1:1
Een speciaal geval is 4:2:0 structuur (zie
tekening 5). Hier wordt een
tussenliggende waarde van twee kleurpixels berekend. Deze methode geeft goede resultaten voor bitstromen onder de
10Mbps maar introduceert verliezen wanneer 4:2:0 terug naar een “hogere”
standaard wordt omgezet.
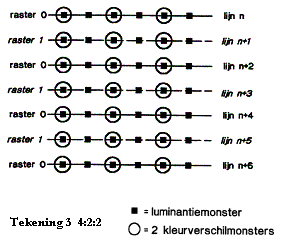
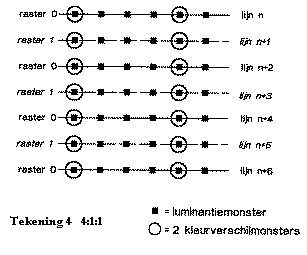
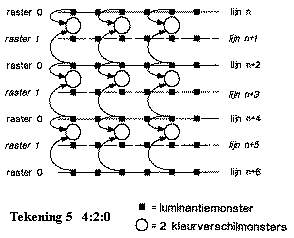
Bij digitale video in de PC-omgeving worden gelijkaardige samplingstructuren gebruikt. Hier komen echter veel meer verschillende resoluties voor.
Een beetje uitzondering is AVI (audio video interleave). AVI is de de-factostandaard voor videocapturing op de PC. 24 BIT RGB is het meest bekende AVI-samplemethode. Alle gebruikelijke grafische toepassingen ondersteunen 24-bit RGB. Per pixel worden 3 bytes gebruikt één voor rood, één voor groen en één voor blauw.
Een voorbeeld:
255 0 0 (een heldere rode pixel in 24 bit RGB)
0 255 0 (een heldere groene pixel in 24 bit RGB)
0 0 255 (een heldere blauwe pixel in 24 bit RGB)
0 0 0 (een zwarte pixel in 24 bit RGB)
255 255 255 (een witte pixel in 24 bit RGB)
128 128 128 (een grijze pixel in 24 bit RGB)
Andere AVI-kleurformaten zijn:
16bit RGB: 5bits voor rood, 6 voor groen en 5 voor blauw
15bit RGB: 5bits voor rood, 5 voor groen en 5 voor blauw (gemakkelijker te implementeren dan 16 bit RGB)
32bit RGB: 1Byte voor rood, 1 voor groen, 1 voor blauw en 1 padding (eenvoudiger te verwerken in een 32 bit-omgeving)
12bit BTYUV 4:1:1 / 16bit YUY2 4:2:2: standaarden gebaseerd op de tv-structuren.
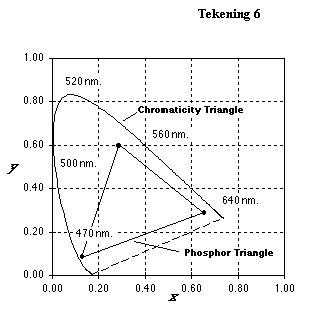
Ten slotte past hier de opmerking dat het kleurenpallet bij TV’s of monitoren niet overeenkomt met die van een pc’s. Met een pc kunnen zogenaamde “onechte” kleuren worden gemaakt die niet kunnen worden weergegeven door een TV of een monitor. Een beeldbuis (driehoek in de tekening) kan door beperkingen van de fosforen slechts een deel van de mogelijke spectrale kleuren (hoefijzermodel) weergeven.
2.1.2.3. Preprocessing
Bij de voorbewerking wordt de complexiteit van de beelden met weinig redundante informatie, verminderd door filtering en ruisonderdrukking. Zo passen complexe beelden na compressie met een minimum aan artefacten [4] in de bandbreedte (vb. ruisreductie heeft een positief effect op bewegingsvoorspelling, DCT, run-length-coding...) Meestal wordt preprocessing niet in de compressiestandaarden opgenomen. Preprocessing parameters kunnen vast of instelbaar zijn.
2.1.2.4. DCT en quantiseren
Een videosignaal heeft een spectrum van 0MHz tot 6MHz. Meestal bestaat een natuurlijk beeld vooral uit informatie in de lagere frequenties. Informatie in de hogere frequenties komt enkel voor bij “randen” in het beeld. Discrete Cosinus Transformatie (DCT) zal de samplewaardes (het tijdsdomein) naar dit frequentiedomein omzetten.
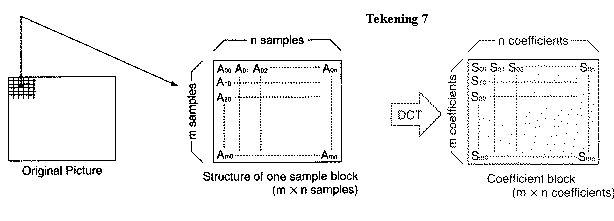
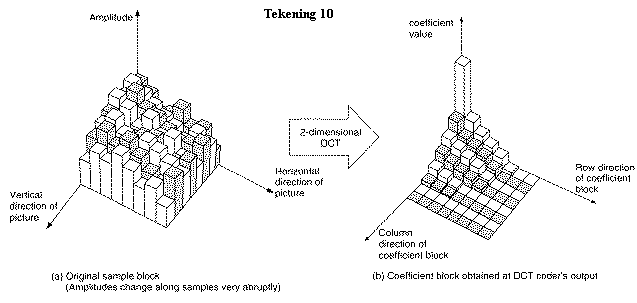
Allereerst wordt het beeld opgedeeld in blokken van m*n samples, de zogenaamde macroblokken. (zie tekening 7)
![]() Op de macroblokken wordt de DCT toegepast (een driehoeksmeetkundige
formule gebaseerd op de Fourier analyse).
De coëfficiënten na deze transformatie geven aan hoe de gesamplede
waardes ten opzichte van elkaar veranderen.
Dit kunnen langzame veranderingen zijn (Tekening 9a) of grillige
veranderingen (Tekening 10a).
Op de macroblokken wordt de DCT toegepast (een driehoeksmeetkundige
formule gebaseerd op de Fourier analyse).
De coëfficiënten na deze transformatie geven aan hoe de gesamplede
waardes ten opzichte van elkaar veranderen.
Dit kunnen langzame veranderingen zijn (Tekening 9a) of grillige
veranderingen (Tekening 10a).
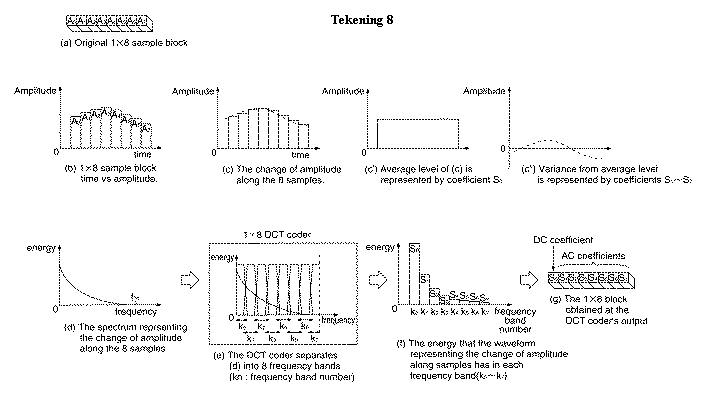
Tekening 8 verduidelijkt het DCT-proces in 1 dimensie (8 samples op een rij). De stippellijn in tekening 8c is de verandering tussen de 8 samples. Ze kan opgevat worden als een DC-component (tekening 8c’) en AC-componenten (tekening 8c’’). De DCT doet eigenlijk hetzelfde. DCT verdeelt het spectrum van de stippellijn (tekening 8d) in 8 frequentiebanden (tekening 8e) en “meet” de mate waarin een frequentieband aanwezig is (tekening 8f). 8 coëfficiënten zijn het resultaat.
De veranderingen worden nu dus uitgedrukt in functie van frequenties (frequentiedomein). Opvallend en typisch voor videobeelden is dat bij de lage frequenties zowat alle mogelijke waardes voorkomen terwijl de hoge frequenties dikwijls 0 zijn (of zeer lage waardes)
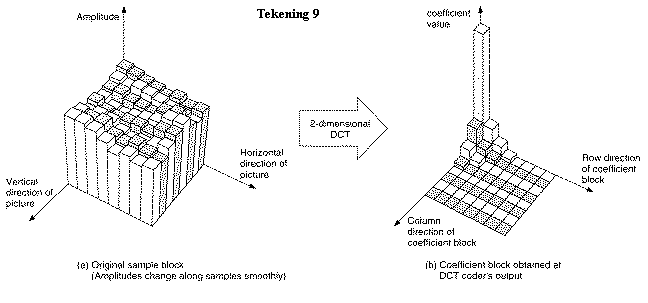
Uit het tweedimensioneel voorbeeld (tekening 9 en 10) blijkt dat de meeste informatie van het macroblok vervat zit in 1 coëfficiënt, DC-component. Ze bepaalt de gemiddelde helderheid van het macroblok.
De samplingstructuur van tekening 10 is grilliger dan die van tekening 9. De coëfficiënten voor de hoge frequenties zijn daar dus hoger.
Na een zigzaguitlezing (tekening 11) krijgen de coëfficiënten een nieuwe binaire code. De coëfficiënten die vaker voorkomen (de lage waardes bij de hogere frequenties) krijgen kortere codes. Het principe van deze variabele lengte codering is vergelijkbaar met de morsecode. Ook daar krijgen letters die veel voorkomen kortere codes. Veel gebruikte coderingen zijn de Huffmancodering en de aritmetische codering [5].
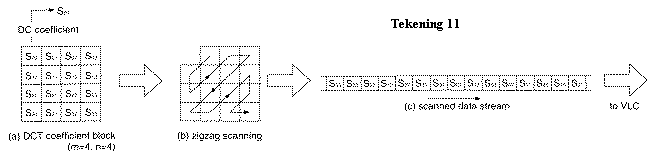
Bovendien zijn coëfficiënten in de hoogste frequenties vaak 0. Deze kunnen dan geschreven worden als “n keer 0” in plaats van “0000000000...0” (run length codering).
De bovenstaande beschrijving van de discrete cosinustransformatie beperkt de bitsstroom echter niet voldoende. Er moet een verliesfactor worden geïntroduceerd. Dit gebeurt in de quantisering (zie tekening 12) net na het DCT-blok. De coëfficiënten uit de DCT-output worden gedeeld door corresponderende waardes uit een quantiseringstabel. Dit vermindert het aantal “mogelijke waardes” van de coëfficiënten waarna men kortere Huffman-codes kan gebruiken. Bovendien worden nog meer coëfficiënten van de hogere frequenties na de deling afgerond naar 0 (efficiëntere run lenght codering). Maar door afrondingen gaat ook informatie verloren.

De coëfficiënten uit de macroblokken zijn echter niet allen even belangrijk. Belangrijke coëfficiënten worden minder “hard” aangepakt. Zo zal de DC-coëfficiënt - de waarde links bovenaan het macroblok die de gemiddelde helderheid aangeeft - door een lagere waarde worden gedeeld. Voor coëfficiënten in de hoge frequenties - de waardes rechts onderaan het macroblok – is het oog minder gevoelig. Zij kunnen door grotere waardes worden gedeeld.
Tekening 13 toont het resultaat van slechte DCT-compressie: zichtbare blokjes !

2.1.2.5.
DWT
“Blocking”
zoals bij de DCT, wordt vermeden met een recentere transformatietechniek: de
DWT (discrete wavelet transformation).
Zoals bij de DCT spreken we van een transformatie omdat de informatie
van één vorm (bij DCT: het tijdsdomein) naar een andere (bij DCT: het
frequentiedomein) wordt omgezet. De
tweede vorm zal compressie toelaten op dezelfde manier als bij de DCT.
Om
“het waarom” van de wavelettransformatie te begrijpen, moeten we eerst de
nadelen van de FT (fourier transformation) en de afgeleide STFT (short term
fourier transformation) bekijken. Op
deze principes is immers de DCT gebaseerd.
Daarna kunnen we vergelijken met de DWT (discrete wavelet
transformation).
De
FT zal een signaal van het tijdsdomein volledig omzetten in het
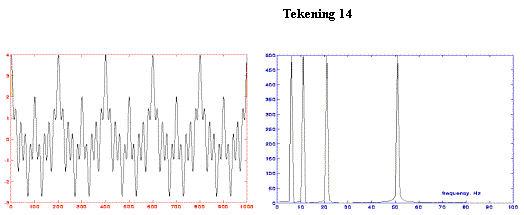
frequentiedomein. Deze transformatie is
perfect voor signalen die niet veranderen in tijd (stationary signals). Tekening 14 toont zo’n stationary signal
(links) en de afgeleide Fouriertransformatie (rechts). Het signaal is opgebouwd uit 4 componenten:
5, 10, 20 en 50 Hz.
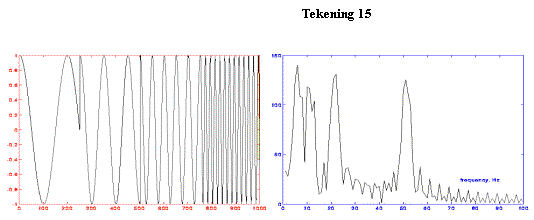
Tekening
15 toont een signaal dat wel in de tijd verandert, een non stationary signal. De FT van dit signaal toont een grote
gelijkenis met de FT van tekening 14.
Ook hier is het signaal opgebouwd uit 5, 10, 20 en 50 Hz. Merk op dat de “ruis” veroorzaakt wordt door
de plotse veranderingen in het oorspronkelijke signaal. Dit is echter onbelangrijk in dit
voorbeeld. Wel belangrijk is dat een FT
dus geen informatie meer bevat van het tijdsdomein. Bij tekening 15 is het dus onmogelijk uit de FT het oorspronkelijke
signaal te reconstrueren.
Een
oplossing voor dit probleem kan zijn het non-stationary-signal op te delen in
stukjes of tijdvensters. Delen we in
tekening 15 het oorspronkelijke signaal in vensters van 250ms, dan bekomen we 4
stationary signals. Hiervan kunnen we
gemakkelijk de FT nemen. Dit principe
noemt men de STFT (short time fourier transformation). De tijdsinformatie gaat hier niet helemaal
verloren.
Maar
er zitten adders onder het gras bij de STFT.
De meeste signalen zien er in de praktijk niet uit zoals tekening
15. De vraag die we ons dan kunnen
stellen is: “Hoe groot moet het window zijn om stationary signals te
krijgen?”.
Bovendien
speelt het zogenaamde Heisenberg-onzekerheidsprincipe mee in dit verhaal. Dit principe heeft normaal te maken met de
plaats en het ogenblik van een bewegend voorwerp. Het kan echter ook worden toegepast op
tijdsfrequentiedomein. Volgens het
Heisenberg-onzekerheidsprincipe kunnen we niet weten welke frequenties bestaan
op welk exact ogenblik. Wat we wel
kunnen weten is welke frequentieband binnen welk tijdsinterval bestaat. Dit is dus een resolutieprobleem.
Bij
tekening 15 gaf een window van 250ms een goed resultaat. Praktische signalen zijn echter heel wat
grilliger. Het is niet moeilijk te
begrijpen dat smalle windows een goede tijdsresolutie maar een slechte frequentieresolutie geven. Grote windows daarentegen geven een slechte tijdsresolutie maar een goede
frequentieresolutie.
Wavelet zal proberen een goede tijdsresolutie (en slechte frequentieresolutie) te geven voor hoge frequenties en een goede frequentieresolutie (slechte tijdsresolutie) voor lagere frequenties. Deze aanpak is zinvol als het signaal hoge frequenties voor een korte tijd en lage frequenties voor een lange tijd bevat. Gelukkig hebben signalen uit de praktijk (ook videosignalen) dikwijls deze eigenschap.
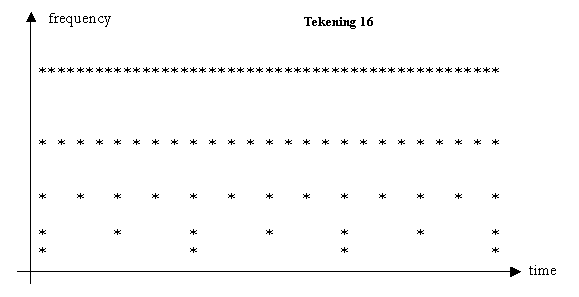
Het principe van DWT is samengevat in tekening 16. De bovenste rij sterretjes toont veel samples met kleine tijdintervallen voor de hoge frequenties (tijds-as). De onderste rij sterretjes, de lage frequenties, hebben grote tijdsintervallen. Bekijken we de frequentie-as dan zien we het omgekeerde. Een goede frequentieresolutie voor lage frequenties en een slechte frequentieresolutie voor hoge frequenties.
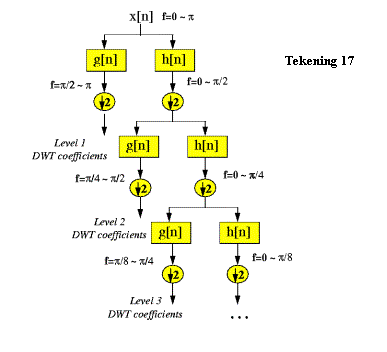
Tekening 17
Tekening 17 beschrijft het DWT-proces. Het originele signaal x[n], met
frequentiesprectrum van 0 tot π rad/s en bijvoorbeeld 256 samples, wordt
aan een laagdoorlaatfilter (h[n]) en een hoogdoorlaatfilter (g[n]) gelegd. Het resultaat van de laagdoorlaatfilter
bevat nu frequenties van 0 tot π/2 rad/s en 256 samples. Het resultaat van de hoogdoorlaatfilter
bevat de frequenties π/2 tot π rad/s en ook 256 samples.
Omdat de twee signalen nu elk de helft van de frequenties bevatten, zijn
volgens het Nyquist-principe ([6]) maar de helft van het aantal samples nodig. Er kan dus worden gedownsampled d.w.z. het
aantal samples verminderen naar vb. 128 (↓2). Dit kan eenvoudig door enkel de even samples te
gebruiken.
Het signaal uit de laagdoorlaatfilter (met frequenties van 0 tot π/2 rad/s en 128 samples) wordt vervolgens nog eens aan een laagdoorlaatfilter (h[n]) en een hoogdoorlaatfilter (g[n]) gelegd. Het resultaat zijn terug twee signalen (0 tot π/4 en π/4 tot π/2 rad/s) met elk 128 samples. Ook deze worden gedownsampled. Enz...
Het proces gaat door tot 2 samples overblijven. Op dat ogenblik zijn er evenveel nieuwe samples als voor de wavelettransformatie. De tijdsfrequentieresolutie heeft nu echter de vorm van tekening 16.
Tekening 15
Het omzetten van het 2D-model in het 3D-model
en het quantiseren kan men vergelijken met de DCT uit de vorige paragraaf. DWT wordt nu wel op het hele beeld toegepast
en niet op macroblokken. Het uitlezen van de coëfficiënten verschilt
wel. Een eerste methode is een soort
zigzagscan waarbij eerst alle laagste frequenties worden uitgelezen, daarna
alle hogere frequenties (meer coëfficiënten dus), daarna alle nog hogere
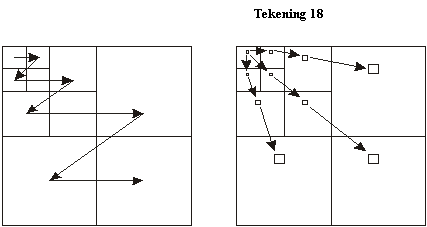
frequenties (nog meer coëfficiënten), enz... . In tekening 18 stellen de
blokjes alle coëfficiënten (1 volledig beeld / horizontaal en verticaal) van 1
frequentie voor. De linkse figuur toont
de zigzaguitlezing. De rechtse figuur
toont een andere vorm: de tree-scan uitlezing.
Hier gebruikt men het parent-child-principe. De coëfficiënten van de lage frequentie zijn de parents. De coëfficiënten van de hogere frequenties,
op dezelfde plaats in het originele beeld, zijn de children van die
parents. Zo wordt een boomstructuur
opgezet. Een belangrijk voordeel van
deze methode is dat parents en childs een grote vorm van gelijkheid
vertonen. Dit kan men gebruiken om te
comprimeren. De meest eenvoudige vorm
van tree-scan-coding is de zerotree-coding.
Als een parent een nulwaarde heeft zullen alle children ook een
nulwaarde hebben.
Vergelijk het resultaat van onderstaande tekening 19 met tekening 13 van de DCT. Blurring (onscherpte) kan optreden bij de DWT maar de blokking is verdwenen.

Voor de reconstructie van een beeld aan de hand van de waveletinformatie, wordt het hierboven beschreven proces omgekeerd. Een interessant voorbeeld van deze reconstructie is de volgende down te loaden demo:
http://www.jpeg.org/public/wavedemo.zip
Op
het internet wordt soms beweerd dat waveletcodering goed is voor still-pictures
maar minder geschikt voor video door moeilijkere interframecompressie. Anderen beweren dat de DWT bij video
dikwijls de DCT overtreft op gebied van kwaliteit/compressie. Enkele kleine visuele testjes die ik zelf
met wavelet-codecs deed, leverden inderdaad goede resultaten op.
2.1.2.6.
VQ
Hoofdstuk
2.1.2.4 beschreef de DCT-quantisering.
Door de DCT-coëffiënten te delen door quantiseringscoëffiënten, worden
bits uitgespaard. Maar zo wordt ook een
verliesfactor geïntroduceerd. Een
voorbeeldje:
Stel dat een digitale sample X,
256 mogelijke waardes kan hebben (8 bits).
Als we de waarde X delen door
bv. 4 en de bekomen waarde afronden naar een geheel getal, hebben we slechts 64
mogelijke waardes. Dit kan voorgesteld
worden door 6 bits. Maar... afronden
betekent verlies. Vector quantisering
of VQ zal proberen die verliezen te beperken.
Ook
bij de omzetting van analoog naar digitaal wordt eigenlijk
“gequantiseerd”. Nog een voorbeeldje:
als een analoge signaal varieert tussen 0 en 1V, kunnen we die schaal
onderverdelen in bv. 32 gelijke stapjes.
Bij het samplen wordt dan met een hoge frequentie het analoge signaal
“gemeten”. Een “meting” kunnen we dan
afronden naar één van de 32 stapjes.
Maar ook hier hebben we te maken met verliezen.
Stel
nu dat in het analoog-digitaal-voorbeeld de signalen meestal rond 0,5V variëren
en zelden de uitersten 0 of 1 V bereiken.
In dat geval zou het interessant zijn de 32 stapjes niet gelijk te
verdelen. In het midden zouden we een
“fijnere” indeling kunnen gebruiken, aan de uitersten een “grovere”
indeling. Uiteindelijk zouden de
afrondingsverliezen dan minder zijn. Op
dit principe is VQ gebaseerd.
En
nu wordt het wat abstract.
Vector-quantisering gebruikt verschillende samples om een indeling te
maken. We nemen eerst 2 samples samen
omdat we dit kunnen voorstellen met een 2D-tekening. Tekening 20 toont de scalar-quantisering (in gelijke stukjes) en
tekening 21 de tegenhanger, de vector quantisering.
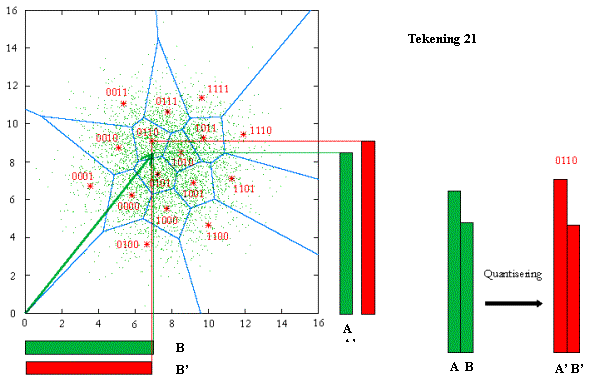
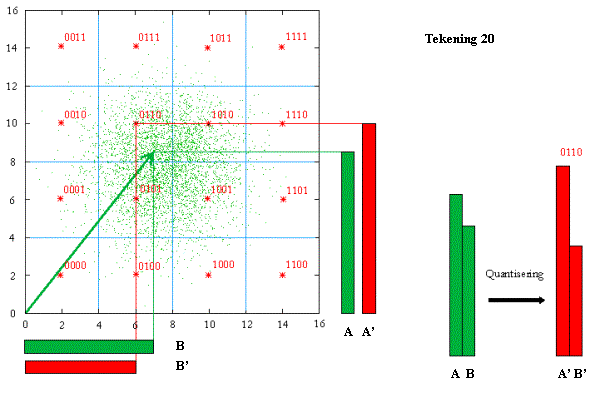
De pijl (de vector) stelt eigenlijk twee “te quantiseren” waardes voor (balkjes A en B). De sterretjes (met een binaire code) zijn de waardes waarnaar men afrondt (de codevectoren). Eén binaire code stelt dus twee gequantiseerde waardes voor (balkjes A’ en B’). Naar welke codevector een vector wordt afgerond, hangt af van de vierkant-structuur bij tekening 20 en de spinnenwebstructuur bij tekening 21.
Waarom kan VQ dan beter zijn? De puntjes in de tekening duiden de plaats aan van andere vectoren. Het is duidelijk dat ze meestal in het midden voorkomen. Door de indeling in het midden “fijner” te maken zullen de afrondingsverliezen over het geheel minder zijn. Vergelijk de voorbeelden rechts op de tekeningen 20 en 21.
Hoe
zo’n spinnenweb opgebouwd kan worden, staat met een mooie animatie op:
http://www.data-compression.com/vqanim.html
Bij videocompressie is
een “vector” gelijk aan een “blokje” samples (meestal 4 horizontaal op 4
verticaal). De vector bestaat dan uit N
dimensies (16 in het geval van 4 op 4).
Moeilijk voor te stellen in een tekening maar wiskundig wel op te
lossen. Het idee van VQ is dat in een
beeld bepaalde patronen meer voorkomen dan andere. Bepaalde “standaard”-blokjes (codevectoren) worden in een aparte
file, een codeboek, bewaard. Het
originele beeld wordt vergeleken met het codeboek en enkel de coördinaten uit het codeboek worden
doorgestuurd.
In het volgende voorbeeld zijn de blokken 1, 2 en 3 bijna gelijk (4*4 pixels met 256 mogelijke helderheidswaarden). De waarnemer zal ze als gelijk beschouwen.
(Block 1) (Block 2) (Block 3)
128 128 128 128 128 127 128 128 128 127 126 128
128 128 128 128 128 128 128 128 128 128 128 128
128 128 75 10 128 128 74 10 127 128 75 10
128 128 10 10 128 128 10 11 128 128 8 10
Ze kunnen dus met 1 vervangingsblokje of één coördinaat uit het codeboek worden voorgesteld.
Lookup Table[1]
128 128 128 128
128 128 128 128
128 128 75 10
128 128 10 10
VQ is wat men noemt asymmetrisch. Dat wil zeggen dat het coderen van het signaal heel traag is, maar het decoderen zeer snel. Coderen vraagt veel tijd en rekenkracht om het originele beeld om te zetten in coördinaten uit het codeboek. Decoderen bestaat enkel uit de code opzoeken in het codeboek en het “standaardblokje” weergeven. De volgende tabel geeft een overzicht van het aantal dimensies (eerste kolom), het aantal bits per blok (tweede kolom), het aantal bits per blok/het aantal pixels per blok (derde kolom), het aantal coördinaten in het codeboek (vierde kolom), het aantal vergelijkingen van pixels uit het blok met de pixels van de blokken uit het codeboek (vijfde kolom). De laatste kolom wordt dus gebruikt bij het coderen. Ze toont dat het aantal bewerkingen snel groot wordt. Het is dan ook niet moeilijk te begrijpen dat het samenstellen van een codeboek nog meer tijd en rekenkracht in beslag zal nemen.
|
block size (N) |
bits/blok |
bits/pixel (R) |
grootte codeboek (L = 2RN) |
n*vergelijkingen (= N2RN) |
|
4 * 4 = 16 4 * 4 = 16 4 * 4 = 16 4 * 4 = 16 8 * 8 = 64 8 * 8 = 64 8 * 8 = 64 8 * 8 = 64 |
4 8 12 16 16 32 48 64 |
0,25 0,5 0,75 1 0,25 0,5 0,75 1 |
16 256 4.096 65.536 65.536 4,3 10 9 281 10 12 18 10 18 |
256 4.096 65.536 1.048.576 4.194.304 275 109 18 1015 1,2 1021 |
Bovendien maakt men codeboeken soms in verschillende niveaus zodat verschillende bitrates ondersteund worden. Moet een sterke compressie worden bereikt, dan kan men minder bits per blok (en dus minder “standaard”-blokjes) gebruiken. Tekening 22a geeft een voorbeeld van de niveaus in een codeboek. Tekening 22b toont het resultaat van een VQ met 7 bits / blok.


De
trend van VQ-beeldcompressie lijkt een beetje voorbijgestreefd. Nochtans zou met de komst van mobiele
applicaties, de VQ-techniek terug interessant kunnen worden. Vele mobiele toestellen hebben beperkte
rekenkracht. Bovendien kunnen wanneer
men de codevectoren afstemt op de modulatietechniek vb. QPSK (quadrature phase
shift keying), transmissiefouten minder
opvallen. Voor de
ISDN-satelliettelefoon is dit echter minder interessant omdat 64Kbps wordt
gegarandeerd en rekenkracht niet echt een probleem is.
2.1.2.7.
Fractale
compressie
De fractal-techniek werd zo’n 15 jaar geleden geïntroduceerd in de wereld van computer-graphics. M. Barsley en het researchteam van het Georgia Institute of Technologie baseerden zich op de IFS (iterated function system)-theorie van Hutchingson om “beelden” zoals landschappen (wolken, bomen en bladeren) te generen. In het bekende boek “Fractals Everywhere” beschrijft M. Barnsley de wiskundige IFS-voorwaarden om een beeld te “maken” met zich herhalende (iterated) functies.
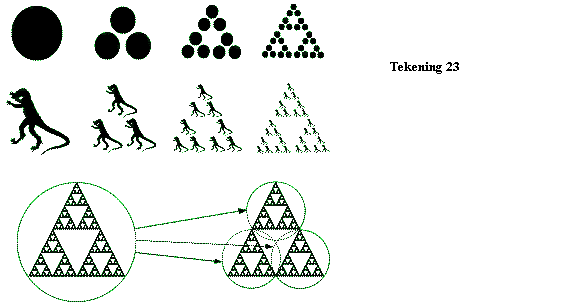
Tekening
23 toont HET voorbeeld van een iterated-functions-system namelijk de Sierpinski-driehoek. Stel
dat een functie eerst een “beginbeeld” verkleint en daarna de drie verkleinde
versies in een driehoeksvorm weergeeft.
Op de drie verkleinde versies kan nog eens dezelfde functie worden
toegepast. En daarop nog eens... (zie tekening 23). De bijzondere eigenschap van een IFS is dat -wanneer de functie
voldoende herhaald wordt- het eindresultaat altijd hetzelfde is. Bij de functie van tekening 23 is dat altijd
de typische Sierpinski-driehoek. Het
beginbeeld mag zowel een “draak” als een gewone cirkel zijn. Het is dus de transformatie die het beeld
beschrijft. Het eindresultaat (waar IFS
naar toe trekt) wordt een attractor genoemd.
De
vraag is of het systeem kan omgedraaid worden.
Vertrekken van een bestaand beeld en dit voorstellen aan de hand van
iterated functions. Dit zou een
serieuze compressie betekenen. Maar het
“omgekeerde” probleem is niet eenvoudig.
De functies vinden voor een gegeven beeld, bleek alleen mogelijk met de
“studenten-theorie”. Sluit een student
op met een grafische PC en wacht tot hij het beeld heeft gereconstrueerd
(reverse-engineering). Het probleem
blijft tot nu niet helemaal opgelost.
Jarquin,
een student van Barnsley, bedacht voor het eerst een oplossing. Het idee is eenvoudig. In plaats van het beeld op te bouwen uit
verkleinde kopies van het HELE beeld, wordt het beeld opgebouwd uit verkleinde
kopies van STUKJES van het beeld. Tekening
24 toont hoe men voor een klein blokje een gelijkaardig groter blok kan
vinden. Het idee van Jacquin noemt men
het partitioned iterated function system (PIFS).

De
meest gebruikte fractal-compressietechniek baseert zich op een vorm van vector-
quantisering. Het is daarom nuttig
eerst MRSG-VQ (main-removed shape-gain vector quantisering) uit te leggen.
Bij
VQ (zie vorige paragraaf) wordt het
beeld opgedeeld in kleine blokje en die worden vergeleken met
“standaard”-blokjes uit een codeboek.
Het berekenen van het codeboek bij VQ is zeer rekenintensief. Daarom bestaan varianten met een
gestructureerd codeboek. Bij
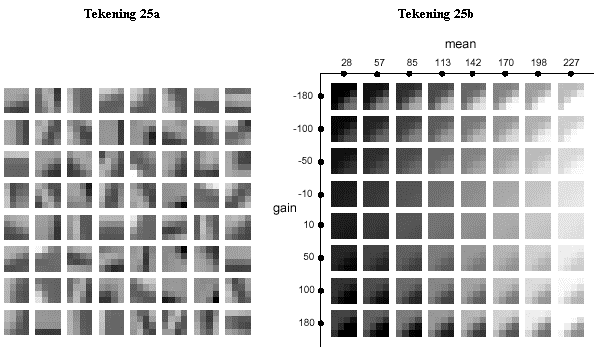
MRSG-VQ wordt bijvoorbeeld een beperkt
codeboek gebruikt (tekening 25a). Maar
elk blokje uit het codeboek kan “bewerkt” worden. Men kan de pixels helderder maken (Mean) en/of in contrast variëren (Gain). Tekening 25a is een “pagina” uit het codeboek
met gain 180 en mean 113. Tekening 25b
toont de verschillende gain- en mean-waardes voor het blokje op de derde rij en
tweede kolom van tekening 25a.
MRSG-VQ
kan men beschrijven met de volgende functie:
R = s * D + o * 1
Hierbij
is R het “originele” blokje; D het “standaard” blokje uit het codeboek; 1
een soort egaal offsetblokje; s de gain en o de mean. Merk op dat men in wiskundetermen uiteraard niet spreekt over
blokjes maar over vectoren met x aantal dimensies (zie vorige paragraaf).
Er
is één groot verschil tussen MSRQ-VQ en fractal-compressie. MRSQ-VQ gebruikt een vast codeboek en
fractal compressie enkel zich-herhalende-functies. Hoe kan een decoder dan een beeld reconstrueren uit het “niets”?
Stel
dat we het getal π = 3,1415… willen voorstellen als een functie: x = s * x + o. Zoals bij tekening 25b kunnen s en o een
aantal vaste waarden hebben (bijvoorbeeld 0.00; 0.40; 0.80; 1.20; 1.60; 2,00
voor o en 0.00; 0.25; 0.50; 0.75 voor s).
|
scale |
offset o |
|||||
|
S |
0.00 |
0.40 |
0.80 |
1.2 |
1.6 |
2.0 |
|
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
|
0.25 |
0.79 |
1.19 |
1.59 |
1.99 |
2.39 |
2.79 |
|
0.50 |
1.57 |
1.97 |
2.37 |
2.77 |
3.17 |
3.57 |
|
0.75 |
2.36 |
2.76 |
3.16 |
3.56 |
3.96 |
4.36 |
Bovenstaande tabel toont dat men π kan benaderen met de
functie x = 0.75 * x + 0.8. Terwijl
men deze functie gemakkelijk kan oplossen, is dat voor blokjes (vectoren in de
wiskunde) niet zo eenvoudig. Dit
laatste kan alleen met herhalende functies.
Stel dat we de functie 0.75 * x + 0.8 herhaaldelijk toepassen op een
willekeurig getal vb 0.8. We krijgen
het volgende resultaat:
x1
= 0.8
x2
= 0.75 * 0.8 + 0.8 = 1.4
x3
= 0.75 * 1.4 + 0.8 = 1.85
x4
= 0.75 * 1.85 + 0.8 = 2.1875
x10
= 3.06...
x30 = 3.1995...
Het resultaat trekt dus naar de
3.2. Dit punt is de attractor van de vergelijking.
De
encoder zal dus moeten zoeken naar functies in de vorm van R = s * D + o * 1
zonder een vast codeboek te gebruiken.
Daarvoor verdeelt men het originele beeld eerst in blokje van
bijvoorbeeld 4*4 pixels, de ranges (R).
Voor elke range-blok zoekt men een domain-blok (D) waarvoor de functie
best past. De domain-blokken bekomt men
door alle mogelijke blokken in het beeld van bijvoorbeeld 8*8 te downsamplen
naar bijvoorbeeld 4*4 pixels.
Het
range-blok zal dus uiteindelijk gecodeerd worden als een verwijzing naar een
groter gedeelte van het beeld en een s- en o-waarde. Het decoderen zal de functie (van elk range-blok) verschillende
malen te herhalen op een willekeurig (meestal zwart) beginbeeld. Zo bekomt men een benadering van het originele
beeld (de attractor van de functies).
Tot
slot nog enkele opmerkingen over fractalcompressie:
1.
Er
is een voorwaarde verbonden aan de gebruikte functies om tot een vast punt
(attractor) te komen. Het noemt het
contractiviteitsprincipe. Het is een
wiskundig begrip dat te maken heeft met “de afstand” tussen de vectoren voor en
nadat de functie werd toegepast. Die
“afstand” moet steeds kleiner worden.
2.
Bij
de meeste fractal-codecs wordt het aantal domain-blokken vergroot door
transformaties op de normale domain-blokken (verkregen door downsampling) toe
te laten. Veelgebruikte transformaties
zijn: spiegelen rond de horizontale, verticale en schuine assen en
90, 180 en 270 graden roteren van bijvoorbeeld het 4*4 blokje. Meer domeinblokken betekent een betere
benadering van het beeld. Maar bepaalde
studies [7] beweren dat meer
mogelijke waardes voor s en o, een gelijkwaardig of zelfs beter effect heeft.
3.
Een
unieke eigenschap van fractal-encoding is dat het beeld niet meer
resolutieafhankelijk is. Het wordt immers
beschreven aan de hand van functies.
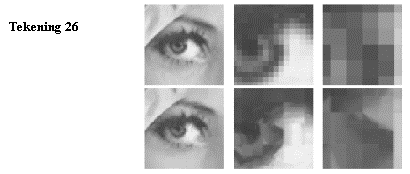
Tekening 26 toont bovenaan een “inzoom” van het originele beeld en
onderaan een “inzoom” van het fractal-gecodeerde beeld. Het is duidelijk dat de details in de
onderste reeks kunstmatig zijn.
4.
De
eerste stap van fractal-encoding was het opdelen van het beeld in
range-blokken. Hiervoor werd een vaste
blokgrootte van bijvoorbeeld 4*4 gebruikt.
Een opdeling die zich aanpast aan het originele beeld zou interessanter
zijn. Gebieden met veel detail kunnen
dan beter worden benaderd met de functies.
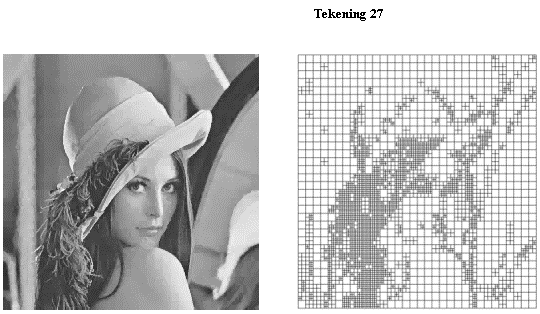
Een voorbeeld is de adaptive quadtree encoder van tekening 27. Hier worden blokken van 4, 8 en 16 pixels
gebruikt.
2.1.2.8.
Motion
compensation
DCT, DWT en VQ
comprimeren elk frame onafhankelijk van de andere frames
(intraframecompressie). De videoframes
onderling bevatten meestal ook een grote vorm van gelijkheid (correlatie). Vooral sterke compressiemethodes (lage
bitrates) maken intensief gebruik van deze motion compensation (interframecompressie).

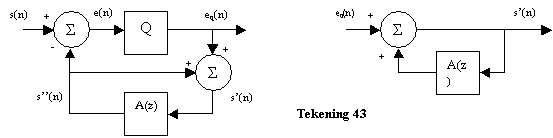
Om interframecompressie te verduidelijken, is het nuttig het begrip DPCM (differential pulse code modulation) uit de intraframecompressie te begrijpen. DPCM gaat ervan uit dat het frame van linksboven naar rechtsonder afgetast wordt. Wanneer de grijze pixels uit tekening 28 bekend zijn, kan men de huidige pixel x(i,j) “voorspellen”. Vele pixels gelijken immers op elkaar (correlatie). De voorspellingsfout (het verschil tussen de voorspelling en de eigelijke pixel) zal dus meestal klein zijn. Deze voorspellingsfout wordt doorgestuurd. De decoder maakt op zijn beurt een gelijkaardige voorspelling en telt er de voorspellingsfout bij op om de pixel te reconstrueren.
Motion compensation volgt een gelijkaardige denkwijze. Er wordt een voorspelling gemaakt aan de hand van één of meerdere “aangrenzende” frames. Enkel het verschil tussen de voorspelling en het echte beeld wordt doorgestuurd. Er bestaan 3 soorten interframes. Afhankelijk van het gebruikte “aangrenzende” frame(s), noemt men ze: I-frames (intra), P-frames (predicted) of B-frames (bidirectional). Een GOP (group of pictures) is een reeks zich herhalende I, P of B-frames (zie tekeningen 29 en 30).
I-frames (intraframes) zijn het eenvoudigst. Ze gebruiken geen interframecompressie, enkel intraframecompressie. Dit soort frames vormen referentiepunten in de videostream. Zonder I-frames zouden foutjes in de interframecompressie, zich blijven opstapelen. Bovendien gebruikt videomontage bijna altijd de I-frames in de videostream om beeldovergangen te maken. Professionele videoformaten comprimeren daarom meestal enkel intraframe (enkel I-frames). Zo kan men bij elk frame gemakkelijk “knippen”. P- of B-frames bij beeldovergangen hebben weinig zin omdat de beeldinhoud volledig verschilt van het vorige frame.

P-frames (Predicted frames) baseren zich op een voorafgaand frame. Dat kan een ander P-frame zijn of een I-frame (zie tekening 29). Een P-frame kan uiteraard met minder bits worden gecodeeerd dan een I-frame.
B-frames (Bi-directional frames) baseren hun voorspelling op een
voorafgaand en een volgend I- of P-frame (tekening 30). Het B-frame kan zo beter voorspeld worden
en de voorspellingsfout wordt dus
kleiner is. Het volgende beeld kan
bijvoorbeeld informatie bevatten dat in het vorig beeld nog niet aanwezig of
bedekt was. Het
nadeel is dat er meer bewerkingen nodig zijn, en dat de transmissievolgorde van
de frames niet hetzelfde is als de oorspronkelijke tijdsvolgorde. Dit vergt extra buffering in encoder en
decoder.
Tekening 31 toont het volledige blokschema van
interframecompressie met I en P-frames.
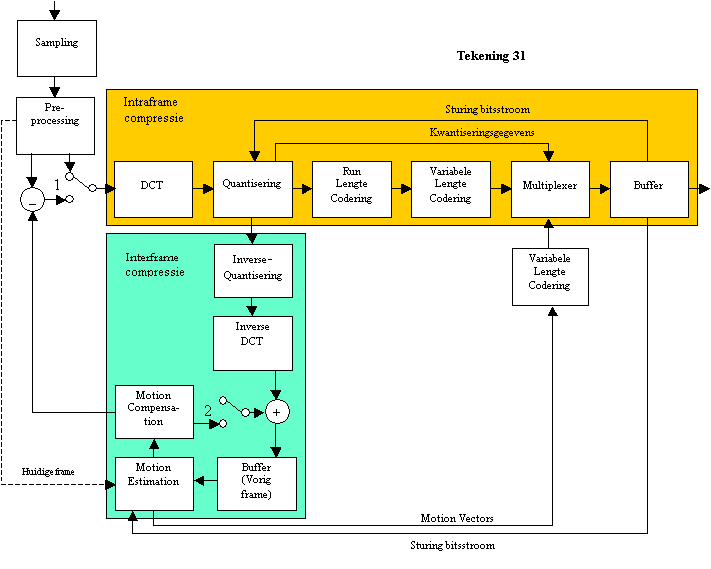
Een overzicht
van de werking :
1.
I-Frame (switch 1 & 2 staan zoals op de
tekening)
·
Enkel het
intraframe-gedeelte wordt gebruikt (zoals uitgelegd in 2.1.2.1)
·
De buffer
wordt gevuld door de inverse quantisering en inverse DCT (omgekeerde
bewerkingen zoals bij de decoder)
2.
P-Frame (switch 1 & 2 staan anders dan op de
tekening)
·
Motion
Estimation: een blok-matchingmethode
zoekt naar “bewegings”-informatie tussen het bufferbeeld en het huidige frame.
·
Motion
Compensation: aan de hand van de “bewegings”-informatie en
het gebufferde frame wordt een “benadering” van het beeld gemaakt.
·
Verschilschakeling: De “benadering” wordt vergeleken met het oorspronkelijke
huidige beeld. De verschillen ondergaan
een DCT en worden gequantiseerd (verdere compressie).
·
De buffer
wordt gevuld met de som van:
1.
het
verschilsignaal (via de inverse quantisering en inverse DCT) en
2.
de “benadering” (uit het motion-compensation-blok).
Bij het gebruik
van B-frames is uiteraard een tweede buffer noodzakelijk.
Hoe de “beweging”-informatie wordt
gevonden is een ander paar mouwen. Laat
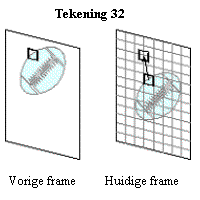
ons terug het voorbeeld van een P-frame gebruiken. Het huidige frame wordt opgedeeld in blokken 8*8 of 16*16 pixels. Voor elk blok zoekt een algoritme een
gelijkaardig blok in het vorige frame (Tekening 32). De “verschuiving” van het blok
kan worden uitgedrukt met een bewegingsvektor.
Merk op dat een
block-matching-algoritme zich baseert op het helderheidsignaal.
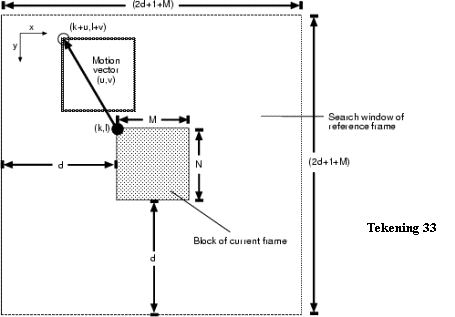
Het bepalen van de bewegingsvectoren is rekenintensief. Onderstaande tabel geeft een overzicht van de MOPS (million operations per second) bij de real-time H.261 videocompressie (gebruikt bij isdn-videoconferencing). Motion estimation neemt duidelijk de meeste berekeningen voor zijn rekening. In de tabel duidt “25 zoekacties in 16*16 window” op een beperking van het blok-matching-algoritme. Het hele vorige beeld onderzoeken op gelijkaardige blokken is onmogelijk. Dit zou te veel tijd en rekenkracht vragen. Er kan enkel in een gebied “rond” de positie van het blok (in het huidige frame) worden gezocht. Dit window wordt getoond in Tekening 33. M en N zijn de afmetingen van het blok. D is de maximumverplaatsing van het blok (horizontaal en verticaal) en x(u,v) is de bewegingsvektor.
|
RGB naar YcbCr |
27 |
|
Motion estimation (16 * 16
window & 25 zoekacties) |
608 |
|
Inter/Intraframe codering |
40 |
|
Filtering |
55 |
|
Pixel prediction |
18 |
|
2-D DCT |
60 |
|
Quantization, zig-zag scanning |
44 |
|
Entropy coding |
17 |
|
Frame
reconstruction |
99 |
|
Total |
968 |
Maar ook binnen
een search-window alle mogelijke bewegingsvector onderzoeken (een fullsearch)
is meestal te rekenintensief. De
volgende tekeningen en een korte beschrijving geven overzicht van de meest
gebruikte zoekalgoritmes.
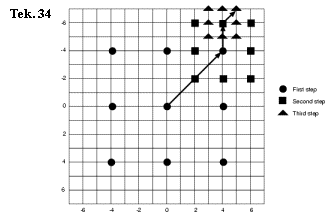
Three-step
search:
1. alle punten op afstand d worden onderzocht (inclusief het middelpunt: geen beweging)
2. voor de beste benadering worden alle punten op een afstand d/2 onderzocht.
3. voor de beste benadering worden alle punten op een afstand d/4 onderzocht.
Tekening 34 toont totaal 25 zoekoperaties
2D-logaritmische
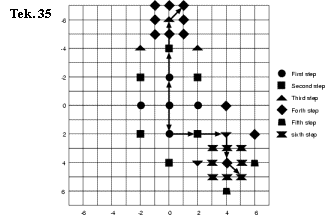
search:
1. telkens worden 5 punten in een +-zoekvorm (met een afstand d/4) onderzocht
2. de afstand wordt d/8 als de zoekactie het midden oplevert of de windowgrens is bereikt. Als de afstand 1 is, worden alle 8 omliggende punten afgelopen.
Tekening 35 toont 2 verschillende zoekacties. De ene met 19, de andere met 23 onderzochte punten.
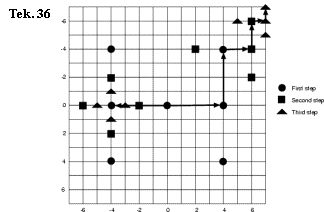
Orthogonal search:
1. er wordt alleen orthogonaal gecheckt. Eerst horizontaal met d/2. Dan verticaal met d/2.
2. het principe wordt herhaald met een stepsize van d/4. Daarna met stepsize d/8 ...
Tekening 36 toont 2 verschillende zoekacties beiden met 13 onderzochte punten.
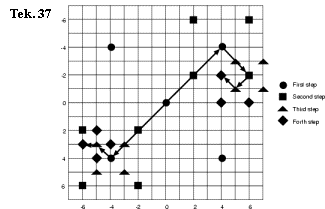
Cross search:
1.
telkens worden 5 punten in een ×-vorm onderzocht. Eerst met
d/2, dan d/4, ...
2.
als
een zoekactie met d=1 het midden, links-boven of rechts-onder oplevert, voert men een extra zoekactie in een +-vorm uit.
3.
als
een zoekactie met d=1 het links-beneden of rechtsboven oplevert, voert men een
extra zoekactie in ×-vorm
uit.
Tekening 37 toont 17 onderzochte
punten
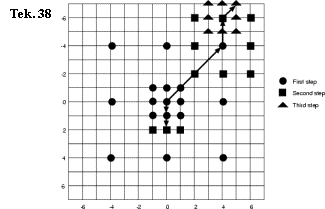
New three-step search: (het basisprincipe is dat beweging meestal in het centrum komt.)
1. eerst worden het midden, 8 punten op d/2 en 8 punten op d=1 gecontroleerd.
2. is het resultaat een punt van het buitenste “vierkant”, dan past men de three-step-search toe.
3. is het resultaat een punt van het binnenste “vierkant”, dan checkt men 3 extra aanliggende punten.
Tekening 38 toont 20 en 33 onderzochte punten
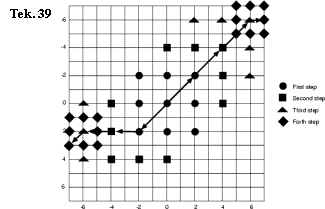
Four-step
search
1. telkens worden de 9 punten op d/4 gecontroleerd.
2. de stepsize wordt 1:
3. aan de rand van het window
4. als de zoekactie het midden oplevert (meestal is er weinig beweging.) Dit noemt men ook de half-way-stop techniek (niet getekend).
Tekening 39 toont 25 en 27 punten. De half-way-stop techniek levert er meestal 17 of 20 op
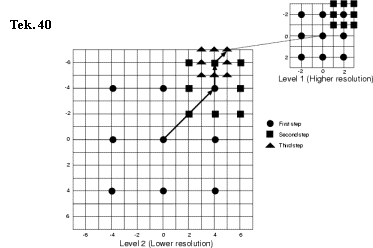
Hierarchical matching algorithm
Dit is eerder een algemeen zoekprincipe.
1. Eerst bepaalt men een ruwe motionvector in een gesubsampled [8] window (level 2 op tekening 40). Dit kan met één van bovenstaande algoritmes.
2. Daarna kan men in een kleiner niet-gesubsampled window, de motionvector verfijnen. Ook dit kan met één van bovenstaande algoritmes (level 1).
Vele coderingssystemen gaan nog verder en berekenen de motionvector tot op een halve pixel nauwkeurig (half-pel-techniek).
Bij blockmatching moet men (1) voor alle blokken uit het frame en (2) voor elke mogelijke motion vector (3) de helderheden van alle pixels van twee blokken “vergelijken”. Verschillende “vergelijkingsmethodes” worden gebruikt: MAE (mean absolute error), MSE (mean square error), MPC (matching pel count) en integral projections.
MAE -ook wel MAD (mean absolute difference) genoemd- is het
populairst. De hardware-implementatie
is vrij eenvoudig. Het
luminantie-verschil tussen de pixel in het ene blok en de overeenkomstige pixel
in het andere wordt berekend. Daarna worden
alle verschillen opgeteld. Formule 1
toont de MAE. m en n zijn de grootte
van het blok, A[ p,q ] is de helderheid van de pixel in de pde rij
en en qde kolom van het eerste blok A.
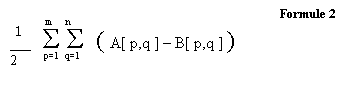
MSE -ook wel MSD (mean square difference)- is gelijkaardig aan
MAE. Hier quadrateert men echter eerst
de verschillen vooraleer ze bij elkaar op te tellen (zie formule 2). Dit zou een beter resultaat geven maar of
dit ook zichtbaar is, is nog maar de vraag.
MSE is niet de methode waarop wij fouten waarnemen.
MPC vergelijkt de corresponderende pixels van de twee blokken en bepaalt of de 2 pixels “gelijk” zijn of niet. Ze zijn gelijk als hun verschil onder een bepaalde grens t (threshold) ligt. Het aantal “matchings” wordt opgeteld. In de formule 3 levert T(xxx) “1” op als de stelling tussen haakjes “true” is en “0” op als de stelling tussen de haakjes “false” is.
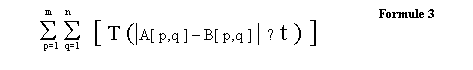
Integral projections worden berekend door de som van de pixels
van een rij te vergelijken. Daarna
worden de som van de pixels van een kolom vergeleken (formule 4). Het voordeel is dat men de sommen kan
hergebruiken bij andere zoekacties in overlappende blokken.
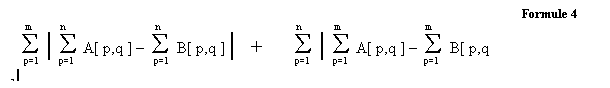
Uit de beschrijvingen van de zoekalgoritmes en de blokmatching-criteria kan men belangrijke conclusies nemen i.v.m. motion detection:
1. Blok-matching detecteert enkel beweging
parallel aan het “camera-vlak”. Zoomen van de camera, rotaties of
3D-bewegingen worden niet ontdekt.
2. Lichtveranderingen in de scène (bijvoorbeeld door bewegende
objecten) worden ook niet ontdekt.
3. Verborgen delen (bijvoorbeeld objecten uit de scène die elkaar
bedekken of een nieuw zichtbaar stukje van de scène bij een camerabeweging) kunnen
niet worden gebruikt voor motion estimation met P-frames. B-frames lost dit probleem voor een deel op.
4. De voordelen van motion-detection worden deels tenietgedaan door
beeldovergangen. Bij het coderen van
een videostream detecteren “slimme”-compressiesystemen beeldovergangen en
plaatsen daar I-frames. Professionele
toepassingen maken enkel gebruik van I-frames om gemakkelijk te monteren.
5. Ruis in het beeld heeft -net als bij intraframecompressie- nadelige
gevolgen bij interframecompressie.
Ondanks deze beperkingen is motion-detection en compensation een heel
krachtig en veel gebruikt compressiesysteem.
Het soort “bewegingsschatter” en de grootte van de GOP’s bepalen
voor een groot stuk de bitreductie maar ook de rekentijd en de nodige buffers.
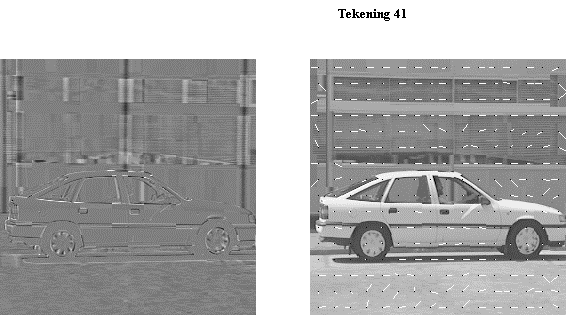
Tekening 41 toont het motion-estimation-proces voor een scène waarbij de
camera een auto volgt (vooral horizontale beweging). Links staat het “voorspelde” beeld en de
motion vectoren, rechts het verschil tussen het voorspelde en het
echte beeld.
Het resultaat
van motion-estimation met eigen afbeeldingen bekijken, kan op de website:
http://extra.cmis.csiro.au/IA/changs/motion
2.1.3. In de praktijk
De volgende pagina’s geven een beknopt overzicht van veelgebruikte standaarden en commerciële codecs. Merk op dat bijna altijd compressietechnieken worden gecombineerd. Dit overzicht is (uiteraard) niet compleet. Alle codecs, varianten, gekraakte versies,... in kaart brengen is moeilijk zoniet onmogelijk.
Voor objectieve testen van videocodecs, verwijs ik naar de site van John McGowan op http://www.jmcgowan.com/avicodecs.html#CodecPerformance. Hier wordt de peak-signal-to-noise-ratio (PSNR) bepaald aan de hand van de main-squared-error tussen het originele en het gecodeerde beeld. (MSE zie 2.1.2.8):
PSNR = 20 log [ b/ (sqrt MSE)] waarbij b de grootste waarde van een pixel is (meestal 255)
PSNR geeft slechts een (wiskundige) aanduiding van de kwaliteit van een codec. Zo zal een beeld met een PSNR boven 35dB als goed en onder de 25 als slecht worden ervaren. Vele andere visuele aspecten zoals blokking, wazige beelden, slechte bewegingen, snelheid van encoderen... spelen een belangrijke rol in de kwaliteitsbeoordeling.

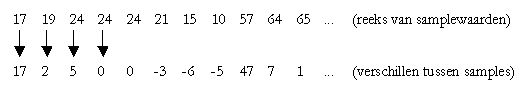


{kind=link}